library(readxl)
library(dplyr)
library(ggplot2)
library(tidyr)4 Jak ramki długie i szerokie
Problem do rozwiązania: transformacja danych z formatu szerokiego do długiego, w celu efektywniejszego wykorzystania możliwości pakietu dplyr i ggplot2.
Słowa kluczowe: data slicing & dicing, pivot_longer, pivot_wider, dplyr,
4.1 Format długi vs. format szeroki
Pozyskując dane z różnych źródeł bardzo często spotykamy się z klasycznym rozwiązaniem, gdzie np. w kolejnych wierszach mamy kroki czasowe, natomiast kolumny są to zmienne, które będziemy analizować. Zmienne mogą odzwierciedlać np. zmienność wartości pewnej cechy w regionach/krajach/jednostkach administracyjnych. Mamy wówczas do czynienia z szerokim formatem danych. Mimo, że z technicznego/programistycznego punktu widzenia analiza takich danych jest jak najbardziej możliwa, to jednak w celu zwiększenia efektywności analiz statystycznych, modelowania, czy też prezentacji danych w ggplot2 bardziej pożądaną jest format długi.
Dane o takiej strukturze tworzymy odpowiednio przetwarzając nasza “klasyczną” ramkę danych, otrzymując w wyniku tej transformacji nową ramkę (można również nadpisać oryginał, ale dopóki nie jest to absolutnie konieczne, np. ze względu na efektywność zarządzania pamięcią w systemie, raczej tego nie polecam).
Załóżmy, że analizujemy dane dotyczące bezrobocia w wybranym wieloleciu w krajach UE. W takim przypadku w formacie szerokim mamy zmienne: ROK oraz kolejne kolumny odpowiadające krajom.
Podczas transformacji do formatu długiego żadne informacje nie są tracone, a my otrzymujemy ramkę danych, która jest “elastyczna” i pozwala oszczędzać czas, wymagając pisania o wiele mniejszej ilości kodu, niż ma to miejsce w przypadku formatu szerokiego. Dla danych dotyczących bezrobocia w krajach europejskich w wieloleciu ramka w formie długiej ma tylko 3 zmienne: ROK, KRAJ oraz STOPA BEZROBOCIA.
Podsumowując. W pracy z danymi, zwłaszcza w R i Pythonie, preferuje się format długi (long format), ponieważ:
jest lepiej dopasowany do narzędzi analizy i wizualizacji danych (np. ggplot2, dplyr),
ułatwia filtrowanie, grupowanie i agregację danych,
współpracuje z modelami statystycznymi (np. lm, glm),
pozwala łatwiej rozbudowywać zestawy danych (nowe zmienne nie wymagają zmian struktury),
lepiej nadaje się do danych złożonych – np. szeregów czasowych, danych panelowych, czy wyników pomiarów z wielu źródeł.
Dzięki temu format długi jest bardziej elastyczny, skalowalny i „zrozumiały” dla większości współczesnych narzędzi analitycznych.
4.2 Dane
Dane wykorzystane w poniższym przykładzie pochodzą z bazy danych EUROSTAT (Eurostat 2025) i są udostępniane na podstawie licencji CC BY 4.0.
Przedstawiają stopę bezrobocia (%) w krajach UE w grupie wiekowej od 15 do 74 lat.
Plik z którego będę importował dane do R można pobrać tutaj.
Nie jest to oryginał z bazy. Skopiowano tylko arkusze dotyczące tego wskaźnika w liczbie osób aktywnych zawodowo (siły roboczej - labour force): 7, 8 oraz 9. Nadano im następujące nazwy: T (F+M), F (kobiety) oraz M (mężczyźni).
Załadujmy zatem niezbędne biblioteki i wczytajmy pliki T, M i F osobno. Za chwilę je połączymy.
Wczytujemy dane.
total <- read_xlsx("data/unemploment_rate_EU_eurostat.xlsx",
sheet = "T",
skip = 9,
na = ":")str(total)tibble [22 × 36] (S3: tbl_df/tbl/data.frame)
$ YEAR : chr [1:22] "2003" "2004" "2005" "2006" ...
$ Belgium : num [1:22] NA NA NA NA NA NA 8 8.4 7.2 7.6 ...
$ Bulgaria : num [1:22] NA NA NA NA NA NA 7.9 11.3 12.3 13.3 ...
$ Czechia : num [1:22] NA NA NA NA NA NA 6.7 7.3 6.7 7 ...
$ Denmark : num [1:22] NA NA NA NA NA NA 6.4 7.7 7.8 7.8 ...
$ Germany : num [1:22] NA NA NA NA NA NA 7.3 6.6 5.5 5.1 ...
$ Estonia : num [1:22] NA NA NA NA NA NA 13.5 16.6 12.3 9.9 ...
$ Ireland : num [1:22] NA NA NA NA NA NA 12.6 14.6 15.4 15.5 ...
$ Greece : num [1:22] NA NA NA NA NA NA 9.8 12.9 18.1 24.8 ...
$ Spain : num [1:22] NA NA NA NA NA NA 17.9 19.9 21.4 24.8 ...
$ France : num [1:22] 8.5 8.9 8.9 8.9 8 7.4 9.1 9.3 9.2 9.8 ...
$ Croatia : num [1:22] NA NA NA NA NA NA 9.2 11.7 13.7 16.1 ...
$ Italy : num [1:22] NA NA NA NA NA NA 7.9 8.5 8.5 10.9 ...
$ Cyprus : num [1:22] NA NA NA NA NA NA 5.4 6.3 7.9 11.9 ...
$ Latvia : num [1:22] NA NA NA NA NA NA 17.7 19.7 16.3 15.1 ...
$ Lithuania : num [1:22] NA NA NA NA NA NA 13.8 17.8 15.4 13.4 ...
$ Luxembourg : num [1:22] NA NA NA NA NA NA 5.1 4.4 4.9 5.1 ...
$ Hungary : num [1:22] NA NA NA NA NA NA 9.7 10.8 10.7 10.7 ...
$ Malta : num [1:22] NA NA NA NA NA NA 6.9 6.9 6.4 6.2 ...
$ Netherlands : num [1:22] NA NA NA NA NA NA 5.4 6.1 6 6.8 ...
$ Austria : num [1:22] NA NA NA NA NA NA 5.7 5.2 4.9 5.2 ...
$ Poland : num [1:22] NA NA NA NA NA NA 8.5 10 10 10.4 ...
$ Portugal : num [1:22] NA NA NA NA NA NA 11.2 12.6 13.5 16.6 ...
$ Romania : num [1:22] NA NA NA NA NA NA 8.4 9 9.1 8.7 ...
$ Slovenia : num [1:22] NA NA NA NA NA NA 5.9 7.3 8.2 8.9 ...
$ Slovakia : num [1:22] NA NA NA NA NA NA 12 14.3 13.5 13.9 ...
$ Finland : num [1:22] NA NA NA NA NA NA 8.3 8.6 8 7.9 ...
$ Sweden : num [1:22] NA NA 7.9 7.2 6.3 6.3 8.5 8.7 7.9 8.1 ...
$ Iceland : num [1:22] NA NA NA NA NA NA 7.2 7.6 7 6 ...
$ Norway : num [1:22] NA NA NA NA NA NA 3.4 4 3.6 3.5 ...
$ Switzerland : num [1:22] NA NA NA NA NA NA NA 4.8 4.4 4.5 ...
$ Bosnia and Herzegovina: num [1:22] NA NA NA NA NA NA NA NA NA NA ...
$ Montenegro : num [1:22] NA NA NA NA NA NA NA NA 19.7 20 ...
$ North Macedonia : num [1:22] NA NA NA NA NA NA 32.2 32 31.4 31 ...
$ Serbia : num [1:22] NA NA NA NA NA NA NA 21.1 25 26 ...
$ Türkiye : num [1:22] NA NA NA NA NA NA 12.6 10.7 8.8 8.2 ...OK, dane dla stopy bezrobocia zostały wczytane, ale jeżeli im się przyjrzymy, to zobaczymy, że dla większości krajów dostępne są od 2009 roku. Pamiętajmy o tym. Później pozbędziemy się okresu, charakteryzującego się znaczną liczbą braków danych.
Wczytujemy pozostałe ramki dla kobiet (F) i mężczyzn (M)
female <- read_xlsx("data/unemploment_rate_EU_eurostat.xlsx",
sheet = "F",
skip = 9,
na = ":")male <- read_xlsx("data/unemploment_rate_EU_eurostat.xlsx",
sheet = "M",
skip = 9,
na = ":")Ze względu na fakt, że struktura danych jest w zasadzie tożsama możemy po prostu połączyć wiersze naszych ramek, wcześniej dodając, do każdej zmienną SEX i przypisując jej odpowiednie wartości. Musimy tak zrobić, ponieważ w przeciwnym wypadku stracilibyśmy informację niezbędną do różnicowania naszych danych ze względu na to kryterium.
total$SEX <- "T"
male$SEX <- "M"
female$SEX <- "F"Połączmy nasze trzy ramki funkcją bind_rows() i utwórzmy obiekt unemp_rt.
unemp_rt <- bind_rows(total, female, male)Usuńmy niepotrzebne ramki danych: T, F oraz M.
rm(list = c("total", "female", "male"))4.3 Ramka szeroka -> ramka długa
Naszym celem jest przetworzenie naszej ramki danych unemp_rt do formatu długiego tworząc nowe zmienne: COUNTRY oraz UN_RT w których zawarte będą informację odnośnie kraju oraz odpowiadającej mu wartości stopy bezrobocia.
Wykorzystamy to tego celu funkcję pivot_longer() i stworzymy obiekt unemp_rt_long
unemp_rt_long <- pivot_longer(unemp_rt,
cols =Belgium:Türkiye,
names_to = "COUNTRY",
values_to = "UN_RT")Podejrzyjmy nasza nową ramkę
str(unemp_rt_long)tibble [2,310 × 4] (S3: tbl_df/tbl/data.frame)
$ YEAR : chr [1:2310] "2003" "2003" "2003" "2003" ...
$ SEX : chr [1:2310] "T" "T" "T" "T" ...
$ COUNTRY: chr [1:2310] "Belgium" "Bulgaria" "Czechia" "Denmark" ...
$ UN_RT : num [1:2310] NA NA NA NA NA NA NA NA NA 8.5 ...Wygląda OK. Mamy 4 zmienne. Zmieńmy jeszcze typ zmiennej YEAR na integer a zmiennej SEX na factor
unemp_rt_long$YEAR <- as.integer(unemp_rt_long$YEAR)
unemp_rt_long$SEX <- as.factor(unemp_rt_long$SEX)Sprawdzamy
str(unemp_rt_long)tibble [2,310 × 4] (S3: tbl_df/tbl/data.frame)
$ YEAR : int [1:2310] 2003 2003 2003 2003 2003 2003 2003 2003 2003 2003 ...
$ SEX : Factor w/ 3 levels "F","M","T": 3 3 3 3 3 3 3 3 3 3 ...
$ COUNTRY: chr [1:2310] "Belgium" "Bulgaria" "Czechia" "Denmark" ...
$ UN_RT : num [1:2310] NA NA NA NA NA NA NA NA NA 8.5 ...Wszystko wygląda poprawnie.
4.4 Przetwarzanie danych
Ramka danych w formie długiej pozwala na efektywna analizę i przygotowywanie wykresów., Załóżmy, że chcemy się przyjrzeć zmienności stopy bezrobocia (bez różnicowania na płeć) dla kilku krajów.
Stwórzmy zatem listę wybranych krajów.
my_countries <- c("Poland","Italy", "Slovakia", "Spain", "Croatia", "Greece", "Germany", "Norway")Poniżej krótki przykład obliczenia wybranych charakterystyk statystycznych (średnia, ekstrema) stopy bezrobocia w wybranych krajach w podziale na płeć dla wielolecia 2009-2024.
unemp_rt_long %>%
filter(COUNTRY %in% my_countries,
YEAR >= 2009,
SEX == c("F", "M")) %>%
group_by(SEX, COUNTRY) %>%
summarise(MEAN = mean(UN_RT),
MAX = max(UN_RT),
MIN = min(UN_RT)
) %>%
head(., n = 16)# A tibble: 16 × 5
# Groups: SEX [2]
SEX COUNTRY MEAN MAX MIN
<fct> <chr> <dbl> <dbl> <dbl>
1 F Croatia 11.5 17 6.7
2 F Germany 4.06 6.9 2.6
3 F Greece 22.4 30.4 12.8
4 F Italy 10.9 13.9 7.3
5 F Norway 3.71 4.3 3
6 F Poland 6.72 11.4 2.9
7 F Slovakia 10.2 14.7 5.9
8 F Spain 19.5 26.7 13.9
9 M Croatia 10.2 16.3 5
10 M Germany 4.51 7 3.4
11 M Greece 15.2 24.8 7.1
12 M Italy 9.1 11.7 6.8
13 M Norway 4.3 5.5 3.4
14 M Poland 5.85 9.7 2.7
15 M Slovakia 8.89 13.9 4.8
16 M Spain 16.9 24.6 10.2Wyniki obliczeń charakterystyk można ponownie przetworzyć do formy długiej i następnie bezpośrednio “przesłać” do ggplot.
unemp_rt_long %>%
filter(COUNTRY %in% my_countries,
YEAR >= 2009,
SEX == c("F", "M")) %>%
group_by(SEX, COUNTRY) %>%
summarise(MEAN = mean(UN_RT),
MAX = max(UN_RT),
MIN = min(UN_RT)
) %>%
pivot_longer(cols = MEAN:MIN,
names_to = "CHARACTERISTIC",
values_to = "UN_RT") %>%
ggplot(., aes(x = COUNTRY, y = UN_RT, color = CHARACTERISTIC))+
geom_point()+
labs(
x = "Country",
y = "Unemployment rate(%)"
)+
facet_wrap(~SEX)+
coord_flip()+
theme_bw()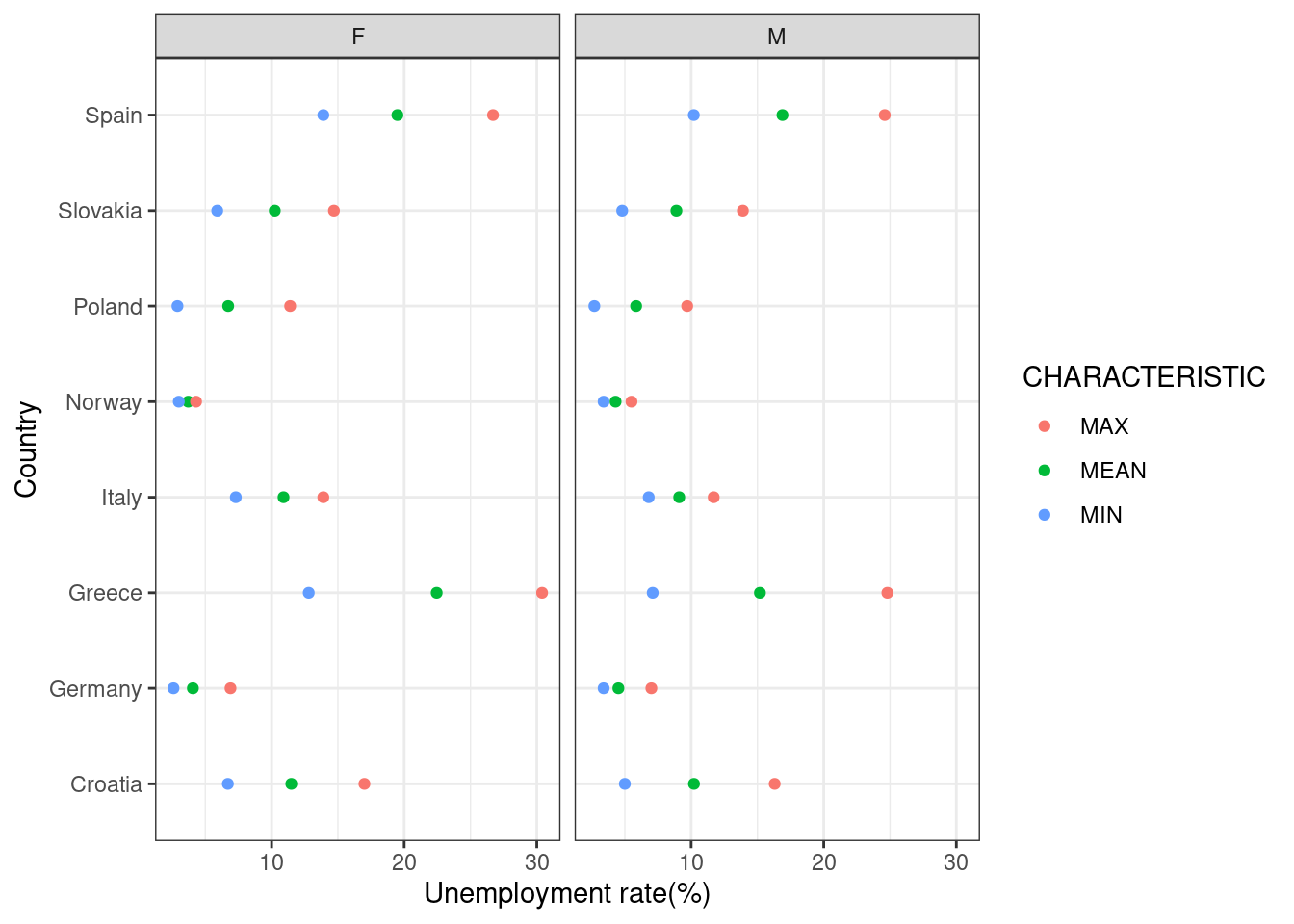
Można również wybrać opcję bez ponownego przekształcenia na formę długą, wykorzystując inną geometrię: geom_errorbar() uzupełnioną o punkt oznaczający wartość średnią. To, czy wymagane jest ponowna transformacja do formatu długiego, uzależnione jest od sposobu mapowania dla wybranej geometrii.
dodge_szerokosc <- 0.6
unemp_rt_long %>%
filter(COUNTRY %in% my_countries,
YEAR >= 2009,
SEX == c("F", "M")) %>%
group_by(SEX, COUNTRY) %>%
summarise(MEAN = mean(UN_RT),
MAX = max(UN_RT),
MIN = min(UN_RT)
) %>%
ggplot(., aes(x = COUNTRY, color = SEX))+
geom_errorbar(aes(ymin = MIN, ymax = MAX), position = position_dodge(width = dodge_szerokosc))+
geom_point(aes(y = MEAN), position = position_dodge(width = dodge_szerokosc))+
labs(
title = "Selected EU countries unemployment rate (%) characteristics",
subtitle = "2009-2024, point: mean, whiskers: min & max",
caption = "Data source: Eurostat",
y = "Unemployment rate (%)",
x = "Country"
)+
coord_flip()+
theme_bw()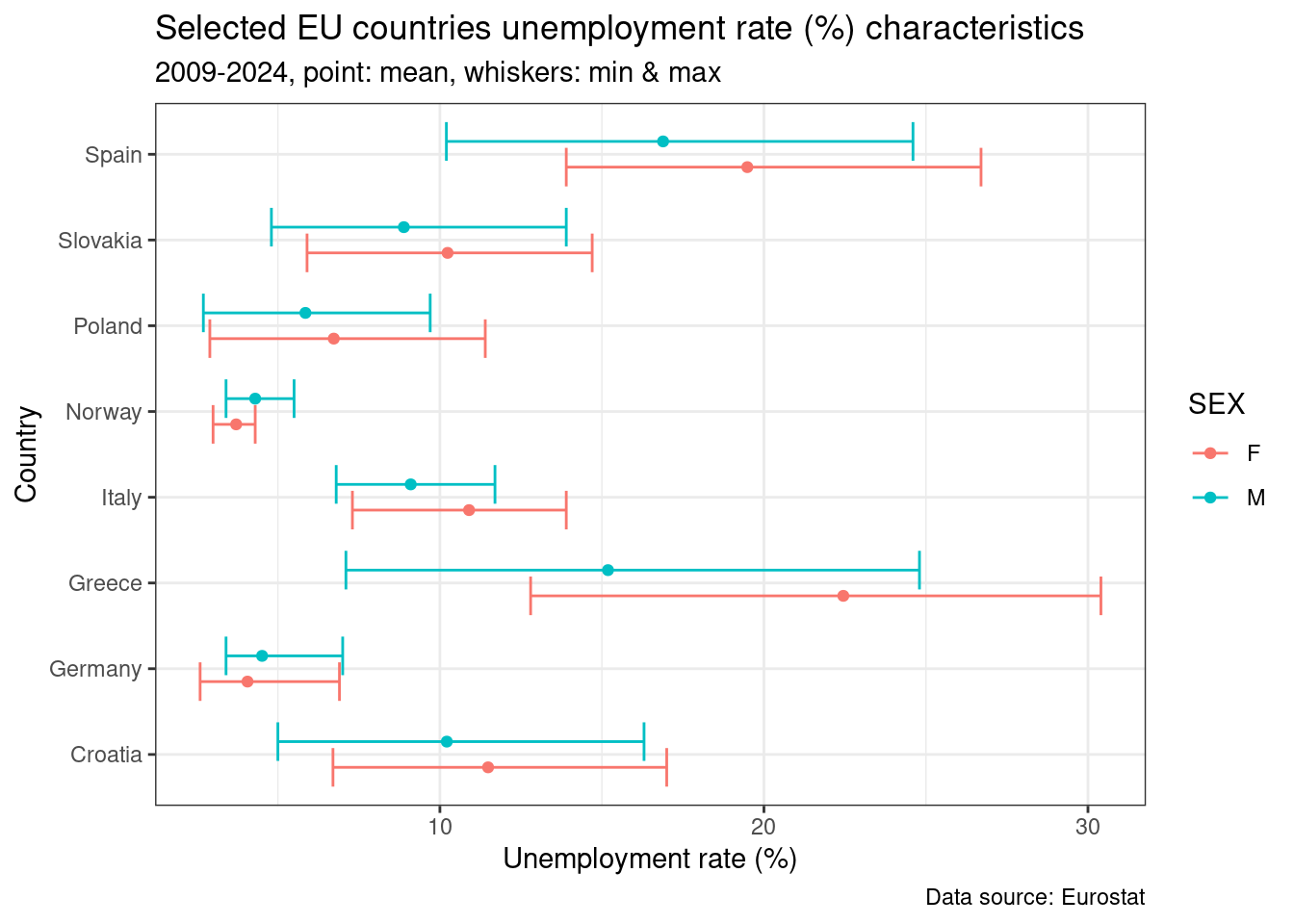
Poniżej całkiem ciekawy trik pozwalający na ułożenie kolejności krajów według np. rosnących/malejących wartości wybranej cechy.
unemp_rt_long %>%
filter(COUNTRY %in% my_countries,
YEAR >= 2009,
SEX == "T") %>%
group_by(COUNTRY) %>%
summarise(MEAN = mean(UN_RT),
MAX = max(UN_RT),
MIN = min(UN_RT)
) %>%
ggplot(., aes(x = reorder(COUNTRY, MEAN)))+
geom_errorbar(aes(ymin = MIN, ymax = MAX), width = 0.4)+
geom_point(aes(y = MEAN))+
labs(
title = "Selected EU countries unemployment rate (%) characteristics",
subtitle = "2009-2024, point: mean, whiskers: min & max",
caption = "Data source: Eurostat",
y = "Unemployment rate (%)",
x = "Country"
)+
coord_flip()+
theme_bw()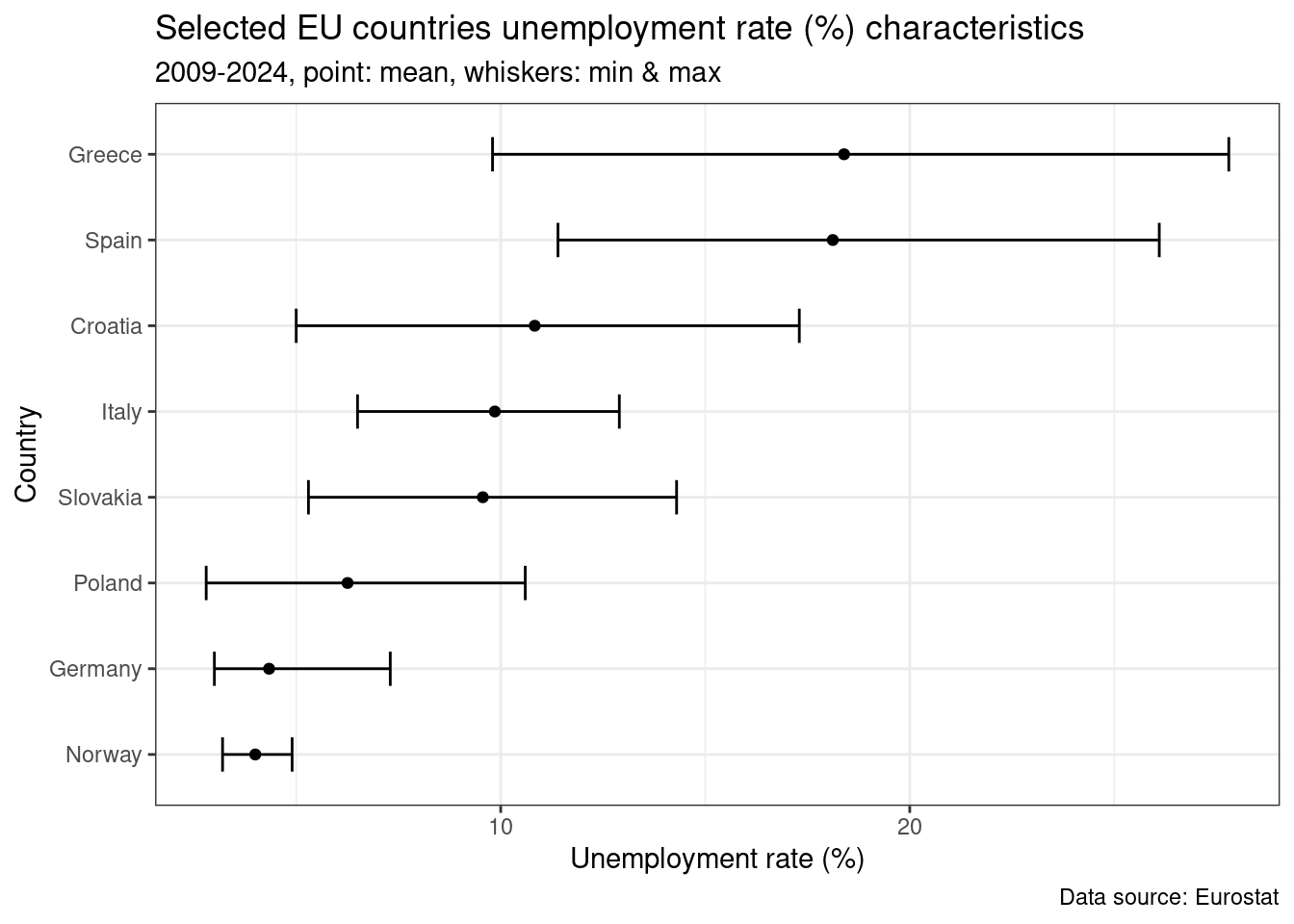
Inny przykład - wykres liniowy tylko dla wybranych krajów od roku 2009, bez podziału według płci. Ponownie posłużymy się przetwarzaniem potokowym i wykorzystamy wynik działań pakietu dplyr bezpośrednio w ggplot2.
unemp_rt_long %>%
filter(COUNTRY %in% my_countries,
YEAR >= 2009,
SEX == "T") %>%
ggplot(., aes(x = YEAR, y = UN_RT, color = COUNTRY))+
geom_line()+
labs(
title = "Unemployment rate for selected EU countries",
subtitle = "2009-2024",
caption = "Data source: Eurostat",
y = "Unemployment rate (%)",
x = "Year"
)+
theme_bw()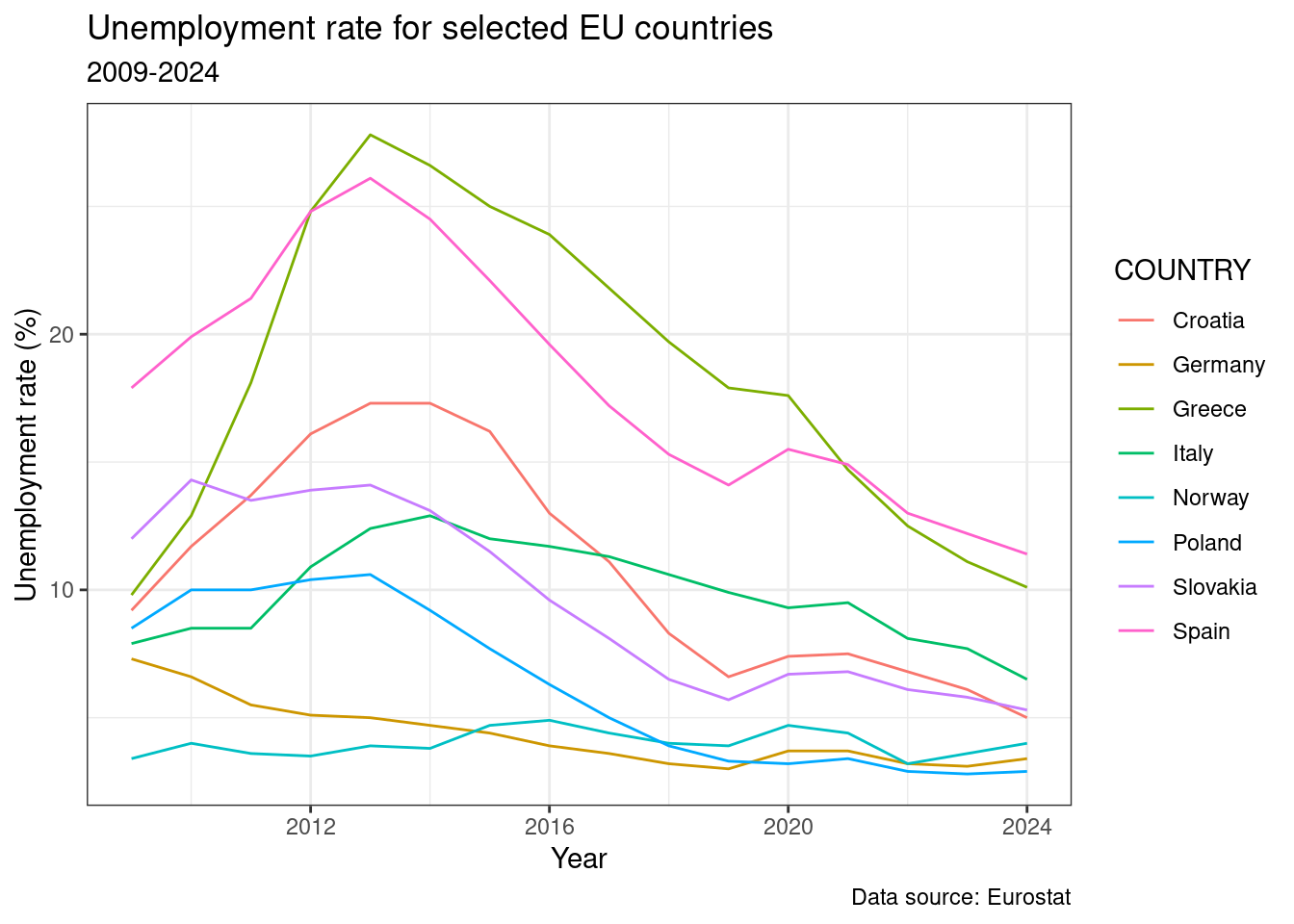
Dzięki temu, że mamy nasze dane w formie długiej możemy bardzo łatwo dodać dla porównania przebieg stopy bezrobocia dla kobiet i mężczyzn.
unemp_rt_long %>%
filter(COUNTRY %in% my_countries,
YEAR >= 2009) %>%
ggplot(., aes(x = YEAR, y = UN_RT, color = COUNTRY))+
geom_line()+
labs(
title = "Unemployment rate for selected EU countries",
subtitle = "2009-2024, F - females, M - males, T - total",
caption = "Data source: Eurostat",
y = "Unemployment rate (%)",
x = "Year"
)+
facet_wrap(~SEX, ncol = 3)+
theme_bw()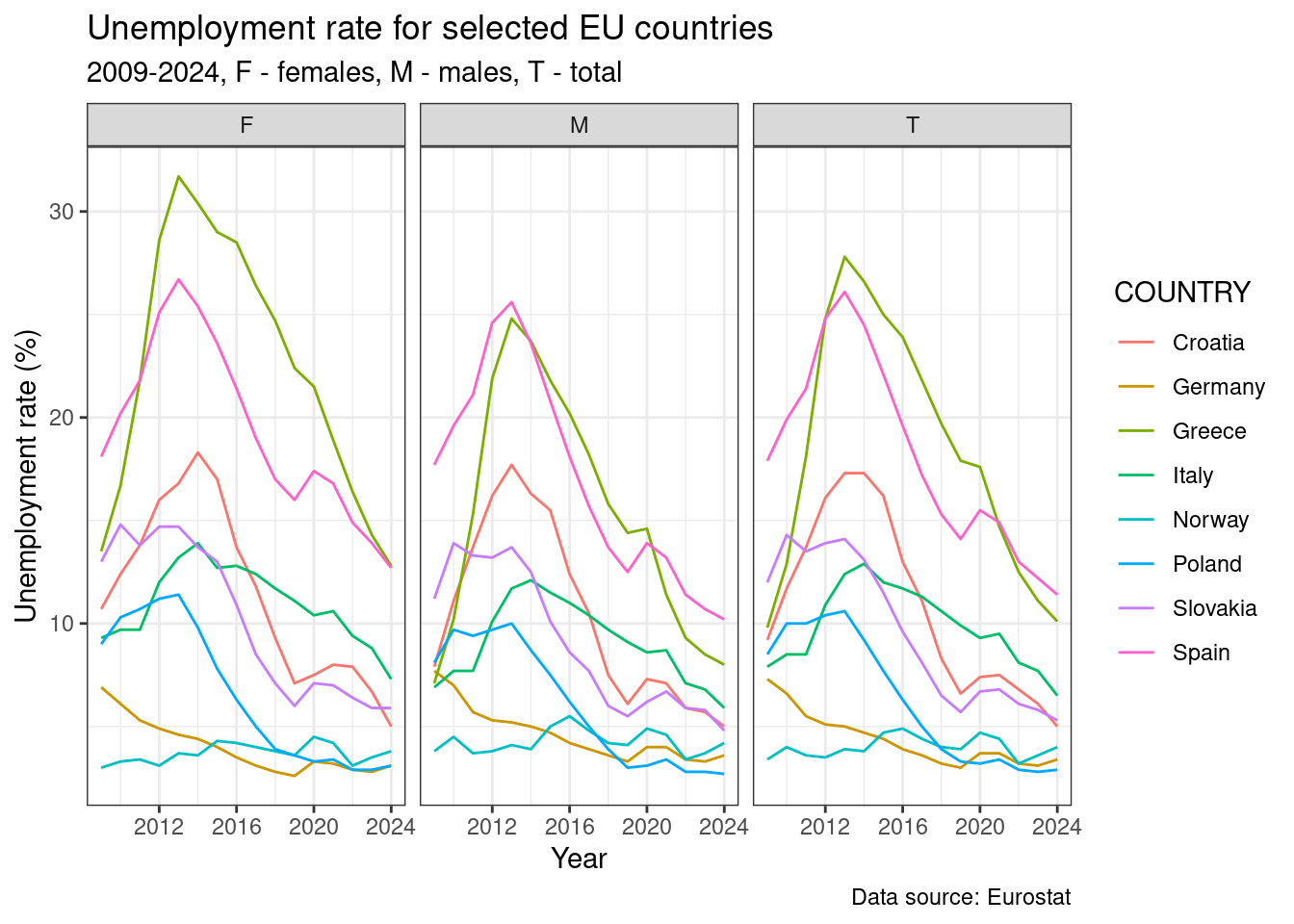
Analiza nie musi się opierać tylko na przebiegu serii czasowych. Można wykorzystać dowolną geometrię z pakietu ggplot2, np. wykresy pudełkowe.
unemp_rt_long %>%
filter(COUNTRY %in% my_countries,
YEAR >= 2009) %>%
ggplot(., aes(x = COUNTRY, y = UN_RT, color = COUNTRY))+
geom_boxplot(size = 0.25)+
labs(
title = "Unemployment rate for selected EU countries",
subtitle = "2009-2024, F - females, M - males, T - total",
caption = "Data source: Eurostat",
y = "Unemployment rate (%)",
x = "Country"
)+
coord_flip()+
facet_wrap(~SEX, ncol = 3)+
theme_bw()+
theme(legend.position = "NULL")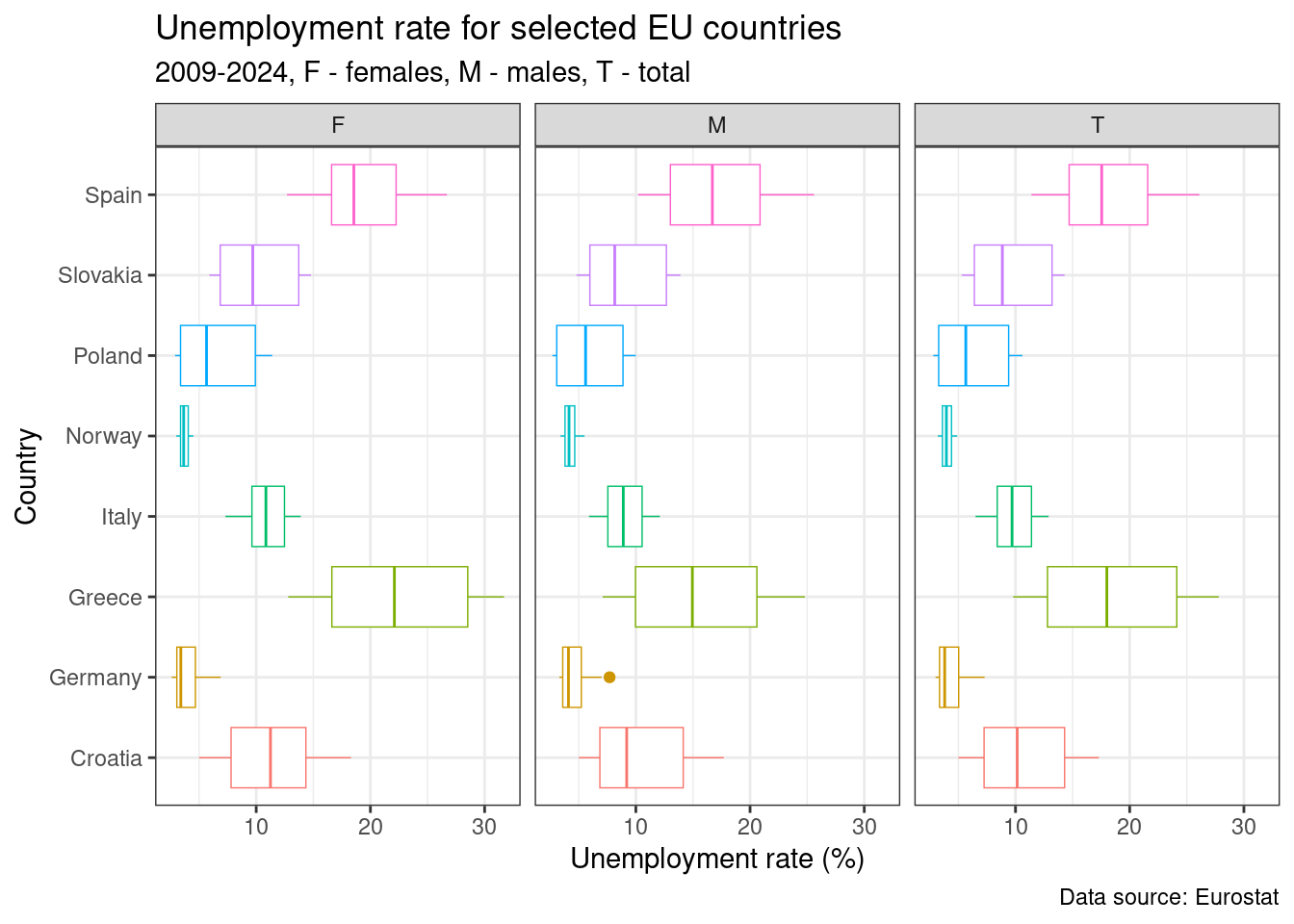
Oczywiście czasami istnieje potrzeba przywrócenia danych do formatu szerokiego. Format długi zmusza do scrolowania i w zasadzie wyklucza efektywną analizę porównawczą danych w tabeli (o ile coś takiego w ogóle istnieje).
Tutaj z pomocą przychodzi funcja pivot_wider(), która pozwala na przekształcenie formatu długiego w szeroki i późniejszego zapisu wynikowego obiektu do jednego z dosyć powszechnych formatów plików np. csv.
Wybierzmy zatem z ramki unemp_rt_long kilka krajów, całkowite bezrobocie bez podziału na płeć, zmieńmy format na szeroki i wyeksportujmy do pliku zewnętrznego.
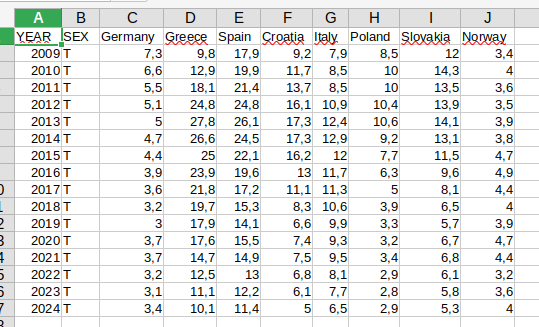
unemp_rt_long %>%
filter(COUNTRY %in% my_countries,
YEAR >=2009,
SEX == "T") %>%
pivot_wider(names_from = COUNTRY, values_from = UN_RT) %>%
write.csv(.,file = "data/Unemployment rate in UE from 2009.csv", row.names = F)Wydaje się, że jest OK. U mnie po otworzeniu w LibreOffice Calc struktura danych wygląda poprawnie (zrzut ekranu poniżej). Nadmiarową zmienną SEX można usunąć, jeżeli nie będzie ona już potrzebna.
Transformacja do formatu długiego znacznie upraszcza analizy oraz prezentację wyników lub surowych danych. Powyższe rozwiązania to tylko próbka możliwości oferowanych przez narzędzia transformacji danych, która jest niezbędnym wstępnym elementem każdej analizy.
Po więcej usystematyzowanych informacji zapraszamy na kursy DataCraft LAB.