library(dplyr)
library(tidyr)
library(ggplot2)3 Wykresy pudełkowe
Problem do rozwiązania: prezentacja zestawu charakterystyk statystycznych w grupach z wykorzystaniem złożonych wykresów, identyfikacja różnic między grupami
Słowa kluczowe: wykresy pudełkowe, różnice między grupami, test Kruskala, test Wilcoxona
3.1 Dane
Dane wykorzystane w niniejszej analizie opisano szczegółowo w rozdziale ?sec-dane.
Załadujmy zatem biblioteki i dane
load("data/t2m_stacje.rda")i kod który będziemy wykorzystywali jako element modyfikacji domyślnego stylu wykresów w ggplot2.
my_style <- theme(text = element_text(size = 14),
panel.border = element_rect(colour = "black", fill = NA, linewidth = 1))Do analizy wybierzemy kilka stacji, ale najpierw zerknijmy jakie stacje mamy do dyspozycji
unique(t2m_stacje$STATION) [1] "BIAŁYSTOK" "BIELSKO_BIAŁA" "CHOJNICE"
[4] "CZĘSTOCHOWA" "ELBLĄG_MILEJEWO" "GDAŃSK_ŚWIBNO"
[7] "GORZÓW_WIELKOPOLSKI" "HEL" "JELENIA_GÓRA"
[10] "KALISZ" "KASPROWY_WIERCH" "KATOWICE_MUCHOWIEC"
[13] "KĘTRZYN" "KIELCE_SUKÓW" "KŁODZKO"
[16] "KOŁO" "KOŁOBRZEG_DŹWIRZYNO" "KOSZALIN"
[19] "KOZIENICE" "KRAKÓW_BALICE" "KROSNO"
[22] "LEGNICA" "LESKO" "LESZNO"
[25] "LĘBORK" "LUBLIN_RADAWIEC" "ŁEBA"
[28] "ŁÓDŹ_LUBLINEK" "MIKOŁAJKI" "MŁAWA"
[31] "NOWY_SĄCZ" "OLSZTYN" "OPOLE"
[34] "PIŁA" "PŁOCK" "POZNAŃ_ŁAWICA"
[37] "RACIBÓRZ" "RESKO_SMÓLSKO" "RZESZÓW_JASIONKA"
[40] "SANDOMIERZ" "SIEDLCE" "SŁUBICE"
[43] "SULEJÓW" "SUWAŁKI" "SZCZECIN"
[46] "ŚNIEŻKA" "ŚWINOUJŚCIE" "TARNÓW"
[49] "TERESPOL" "TORUŃ" "USTKA"
[52] "WARSZAWA_OKĘCIE" "WIELUŃ" "WŁODAWA"
[55] "WROCŁAW_STRACHOWICE" "ZAKOPANE" "ZAMOŚĆ"
[58] "ZIELONA_GÓRA" przetwórzmy naszą ramkę danych tak, aby zawierała informacje jedynie dla stacji: ŁEBA, KRAKÓW_BALICE, MIKOŁAJKI, WROCŁAW_STRACHOWICE, ZAMOŚĆ.
Wybierzmy również okres czasu analizy rozpoczynający się od roku 1951, a kończący na roku 2020 (70 lat).
Zapiszmy nasze dane do dalszych analiz jako data.
data <- t2m_stacje %>%
filter(STATION %in% c("ŁEBA", "KRAKÓW_BALICE", "MIKOŁAJKI", "WROCŁAW_STRACHOWICE", "ZAMOŚĆ")) %>%
filter(YEAR >= 1951, YEAR <= 2020)I ponownie sprawdźmy, czy wybraliśmy stacje i poprawny zakres lat.
unique(data$STATION)[1] "KRAKÓW_BALICE" "ŁEBA" "MIKOŁAJKI"
[4] "WROCŁAW_STRACHOWICE" "ZAMOŚĆ" range(data$YEAR)[1] 1951 20203.2 Wykresy pudełkowe
W świecie danych nie zawsze potrzeba skomplikowanych wykresów, by dotrzeć do wartościowych wniosków. Czasem to właśnie prostota jest kluczem do skutecznej analizy. Wykres pudełkowy (box plot) to jeden klasycznych typów wizualizacji, który – choć nieskomplikowany – potrafi błyskawicznie odsłonić kształt rozkładów wybranych zmiennych, wskazać istnienie wartości odstających i pomóc w porównaniu grup między sobą. A dzięki ggplot2 w R, jego stworzenie staje się intuicyjne, estetyczne i elastyczne.
Wykresy pudełkowe to doskonałe narzędzie w sytuacjach, gdy:
chcemy porównać rozkład zmiennej liczbowej w różnych grupach,
interesuje nas zakres, mediana i kwartyle,
potrzebujemy szybkiej diagnozy wartości odstających.
Box plot nie pokazuje wszystkiego – nie oddaje np. szczegółów rozkładu tak dobrze jak wykres gęstości prawdopodobieństwa – ale świetnie sprawdza się w analizach porównawczych oraz w komunikacji wyników z osobami nietechnicznymi.
Podstawowy wykres pudełkowy możemy wykreślić wykorzystując geometrię geom_boxplot
ggplot(filter(data, MONTH == 1), aes(x = STATION, y = T2M))+
geom_boxplot(staplewidth = 0.5)+
theme_bw()+
my_style+
coord_flip()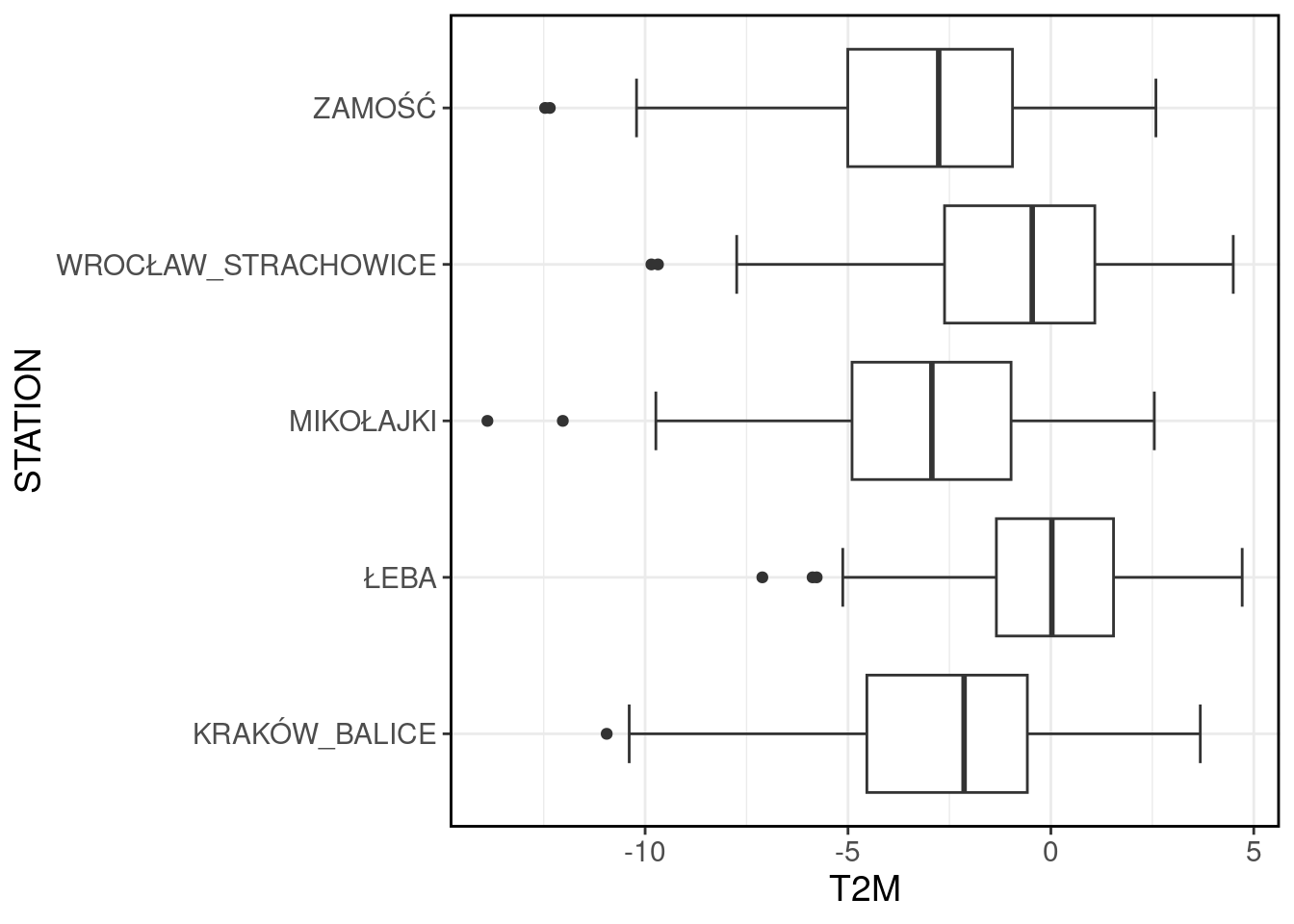
Domyślnie wykres taki pokazuje zestawienie podstawowych charakterystyk:
pudełko: kwartyl 1, mediana, kwartyl 3,
wąsy: kwartyl 1 - 1.5*IQR, kwartyl 3 + 1,5*IQR.
punkty: obserwacje odstające nie mieszczące się w zakresie wyznaczanym przez wąsy.
Jeżeli tak obliczone pozycje wąsów przekraczają wartości minimum lub maksimum to ich długość jest redukowana do wartości ekstremalnych.
Osobiście nie przepadam za tym klasycznym tukey’owskim rozwiązaniem.
Preferuję wykorzystanie kwantyli 10% oraz 90% ewentualnie 5% i 95%. Z punktu widzenia analizy tego typu podejście jest zdecydowanie bardziej uzasadnione, a identyfikacja wartości ekstremalnych, jako wykraczających poza zakres zdefiniowany przez wybrane kwantyle, ułatwia interpretację, szczególnie kiedy w grę wchodzi porównywanie charaktetrystyk między grupami.
Nie będę tutaj wprowadzał w szczegóły tego rozwiązania, zaprezentuję tylko jego wynik.
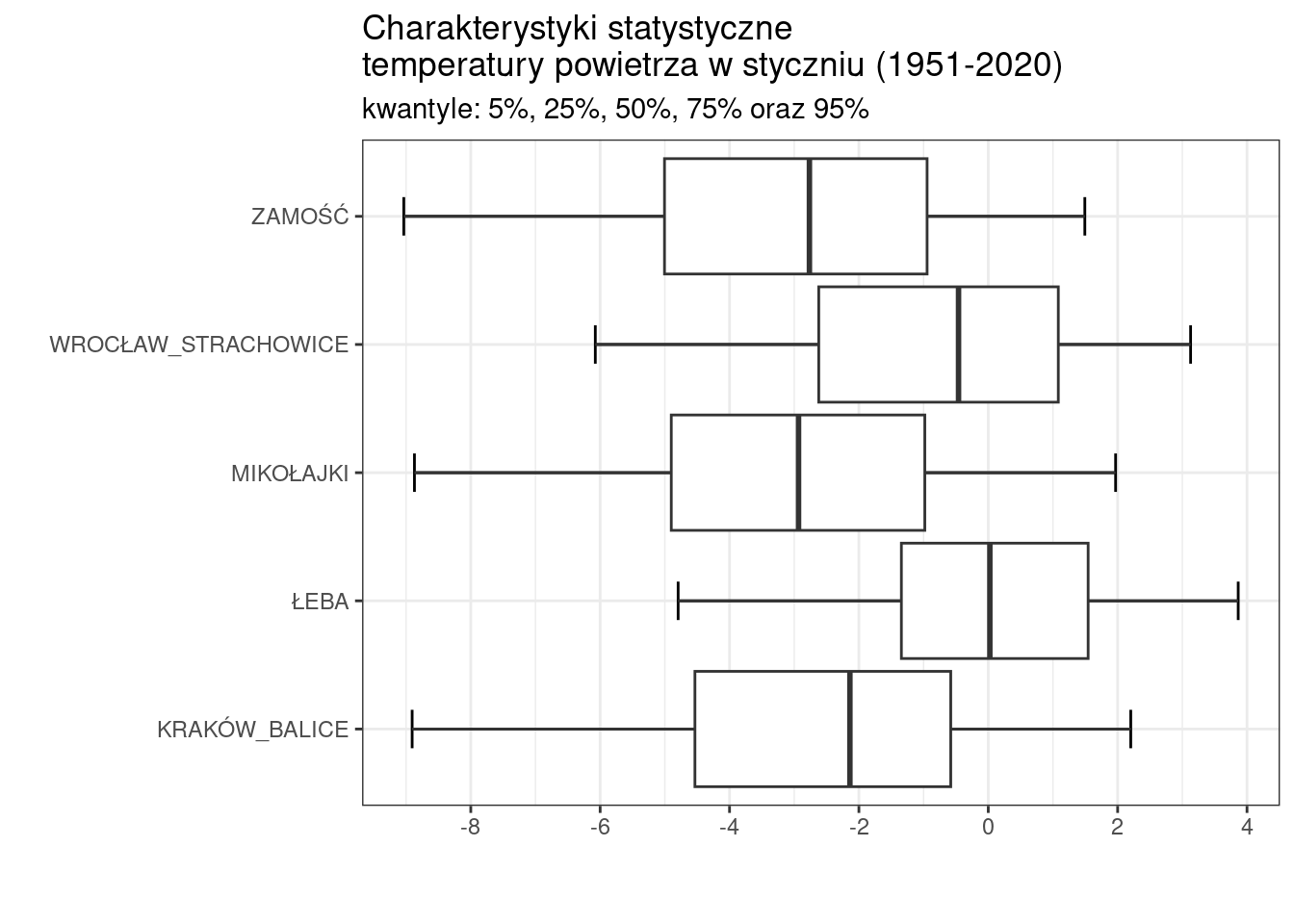
Nie ma również przeciwwskazań, aby zastosować wykres pudełkowy w nieco bardziej skomplikowanych układach graficznych, np. dla dwóch wybranych miesięcy.
ggplot(filter(data, MONTH %in% c(1, 7)), aes(x = STATION, y = T2M))+
geom_boxplot(staplewidth = 0.5)+
coord_flip()+
facet_wrap(~MONTH)+
theme_bw()+
my_style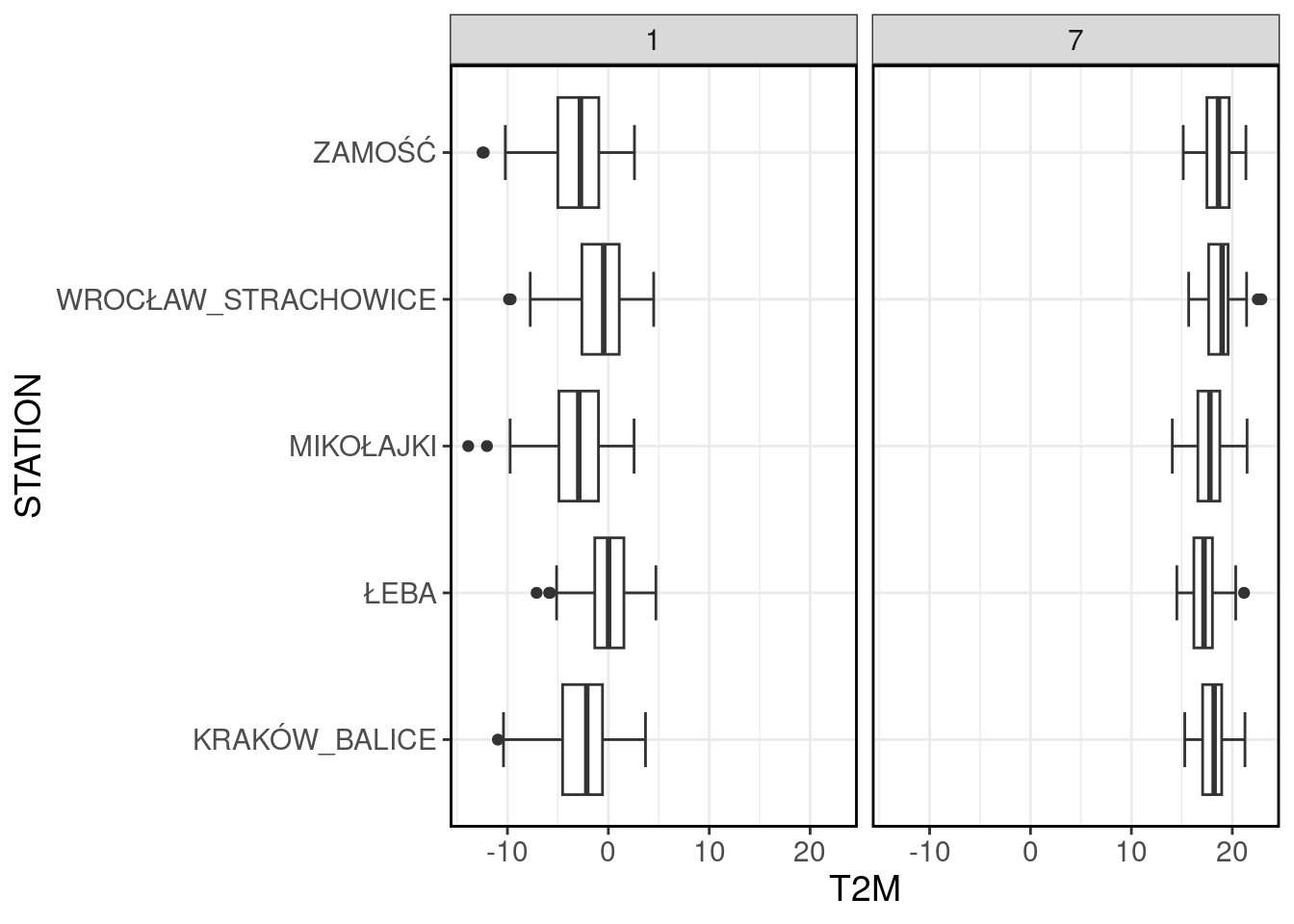
W przypadku ewidentnego cyklu rocznego pojawia się problem “marnowania” znacznej przestrzeni na wykresach z dodatkowym ograniczeniem możliwości interpretacji poprzez “ściśniecie” wykresów. Jest to powodowane wymuszeniem unifikacji skali dla zmiennej T2M.
Można to oczywiście wyłączyć, uzyskując żądany efekt, niemniej jednak, w przypadku bardziej skomplikowanych wykresów, może to utrudnić ich analizę, lub spowodować znaczną redukcję obszaru wykresu, czyniąc go w zasadzie nieczytelnym. Poniżej ponownie przykład dla stycznia i lipca.
ggplot(filter(data, MONTH %in% c(1, 7)), aes(x = STATION, y = T2M))+
geom_boxplot(staplewidth = 0.5)+
coord_flip()+
facet_wrap(~MONTH, scales = "free_x")+
theme_bw()+
my_style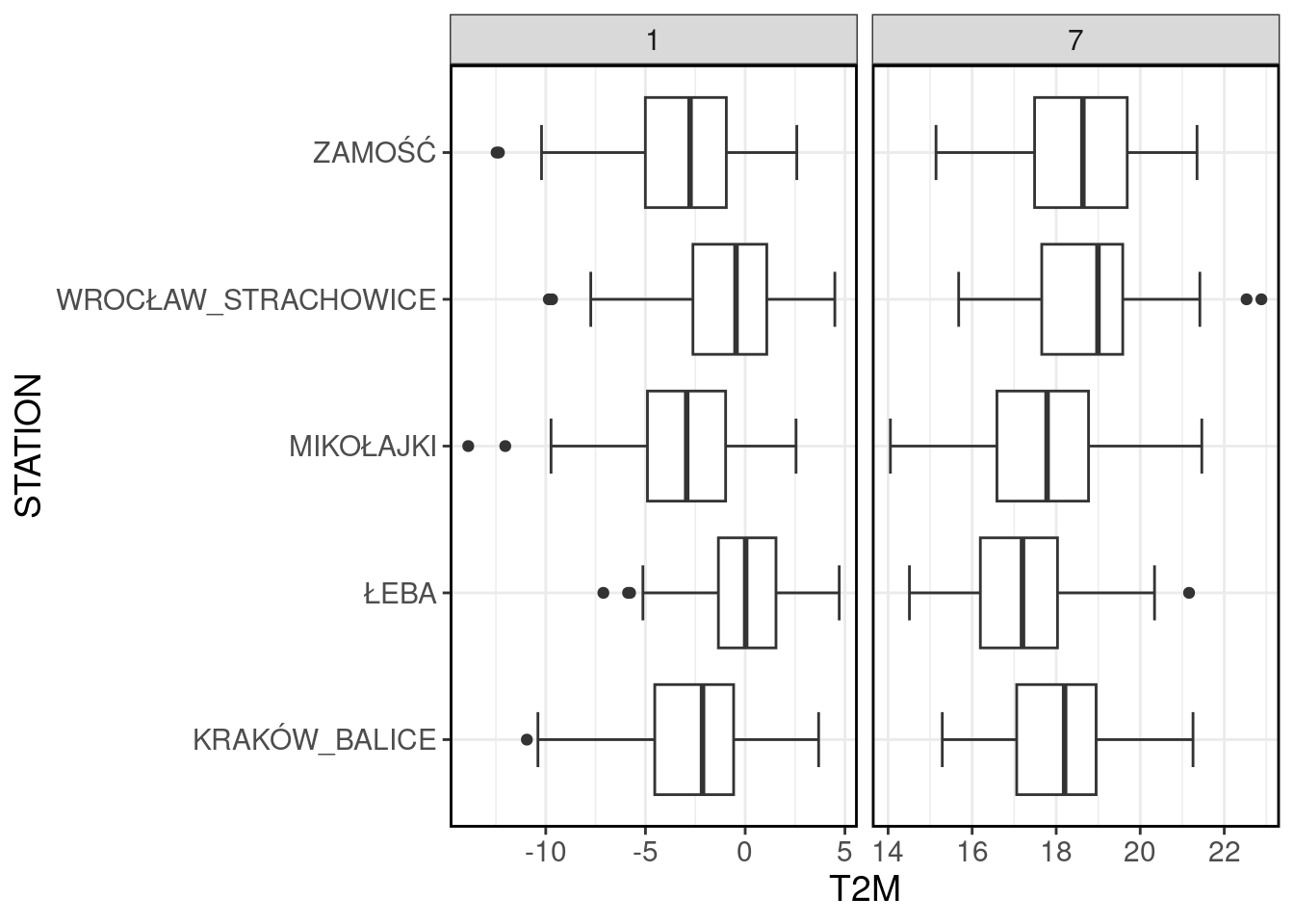
Możliwości wykresów pudełkowych bynajmniej się na tym nie kończą. Załóżmy, że chcemy porównać charakterystyki statystyczne 3 okresów 20 letnich: 1961-1980, 1981-2000, 2001-2020 dla wartości średniej temperatury powietrza z sezonu letniego(czerwiec, lipiec i sierpień) powyższych stacji.
Najpierw przygotujemy nasze dane oraz opatrzymy je dodatkową kolumną ze zmienną DEKADA
data_dekady <- data %>%
filter(MONTH %in% c(6, 7, 8), YEAR >= 1961, YEAR <= 2020) %>%
group_by(STATION, YEAR) %>%
summarise(T2M_SUMMER = mean(T2M)) %>%
mutate(DEKADA = case_when(
YEAR >= 1961 & YEAR <=1980 ~ "1961-1980",
YEAR >= 1981 & YEAR <=2000 ~ "1981-2000",
YEAR >= 2001 & YEAR <=2020 ~ "2001-2020"
))I boxplot dla dekad
ggplot(data_dekady, aes(x = DEKADA, y = T2M_SUMMER))+
geom_boxplot()+
labs(
y = "Temperatura powietrza [°C]"
)+
facet_wrap(~STATION)+
theme_bw()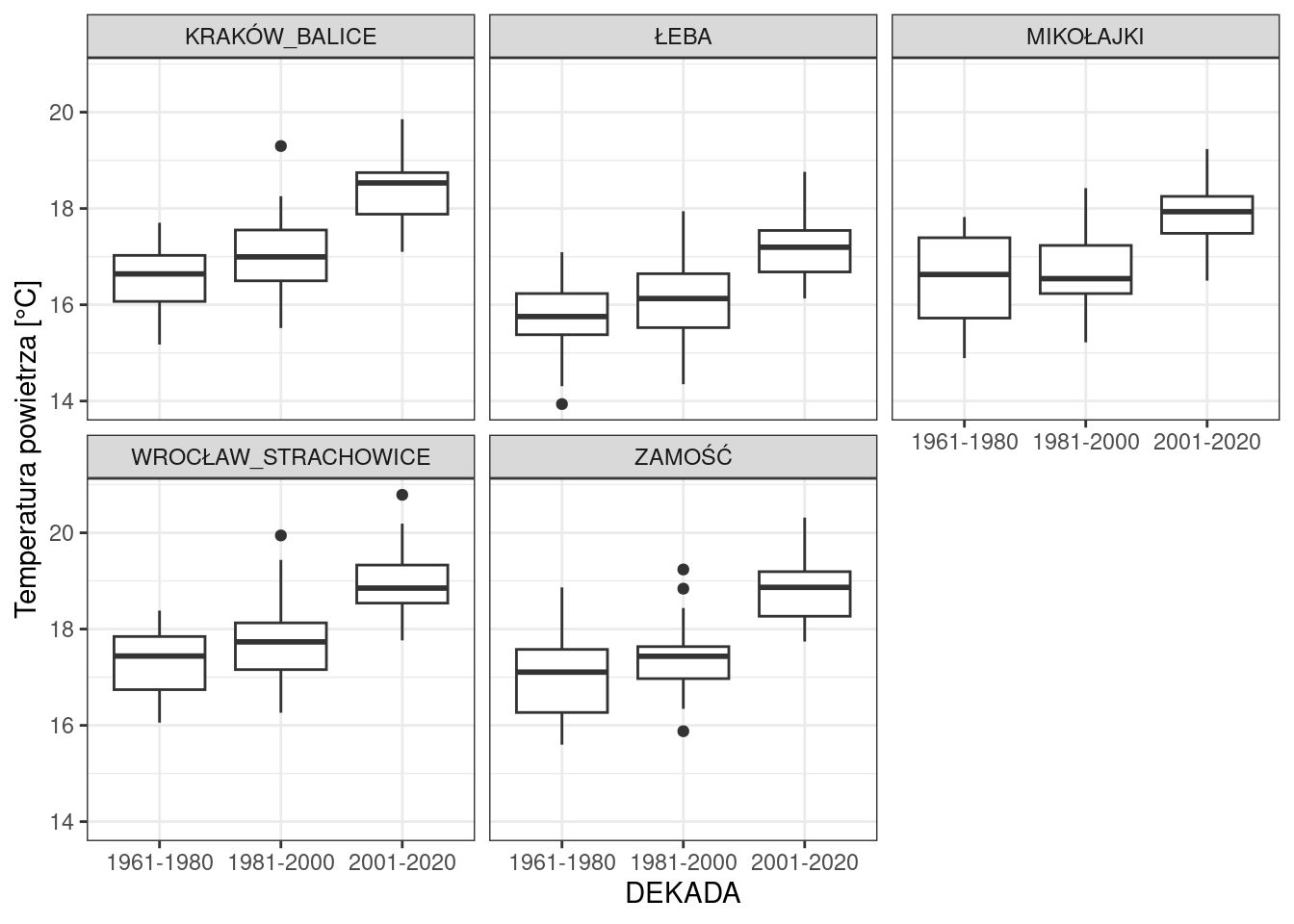
Wykorzystując dodatkową paczkę ggpubr można wykres tego typu uzupełnić o wyniki testów statystycznych dotyczących istotności różnic generowanych przez zmienną grupującą i np. zastosować test Kurskal’a weryfikujący istnienie “globalnej” różnicy oraz test Wilcoxon’a weryfikujący istnienie różnic między wskazanymi grupami.
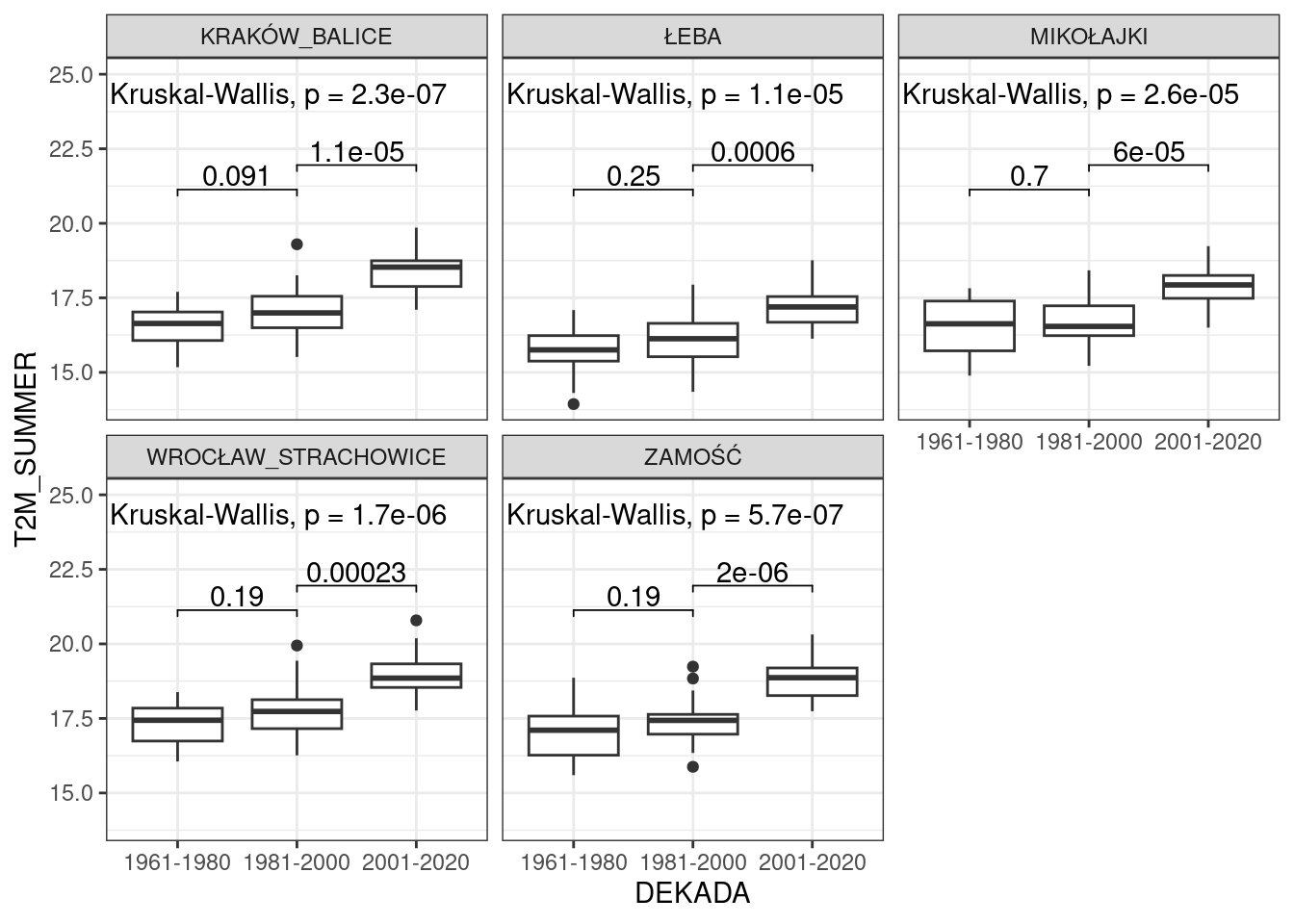
Powyższe stanowi jedynie wycinek możliwości R.
W kontekście grafiki można wspomnieć o estymatorach gęstości prawdopodobieństwa (jedno lub dwuwymiarowych), a w kwestiach bardziej sformalizowanych możliwość zastosowania szerokiego wachlarza testów statystycznych.
Po więcej zapraszamy na kursy DataCraft LAB.