zmienna1 <- rnorm(1000)
zmienna2 <- rnorm(1000)
plot(zmienna1, zmienna2)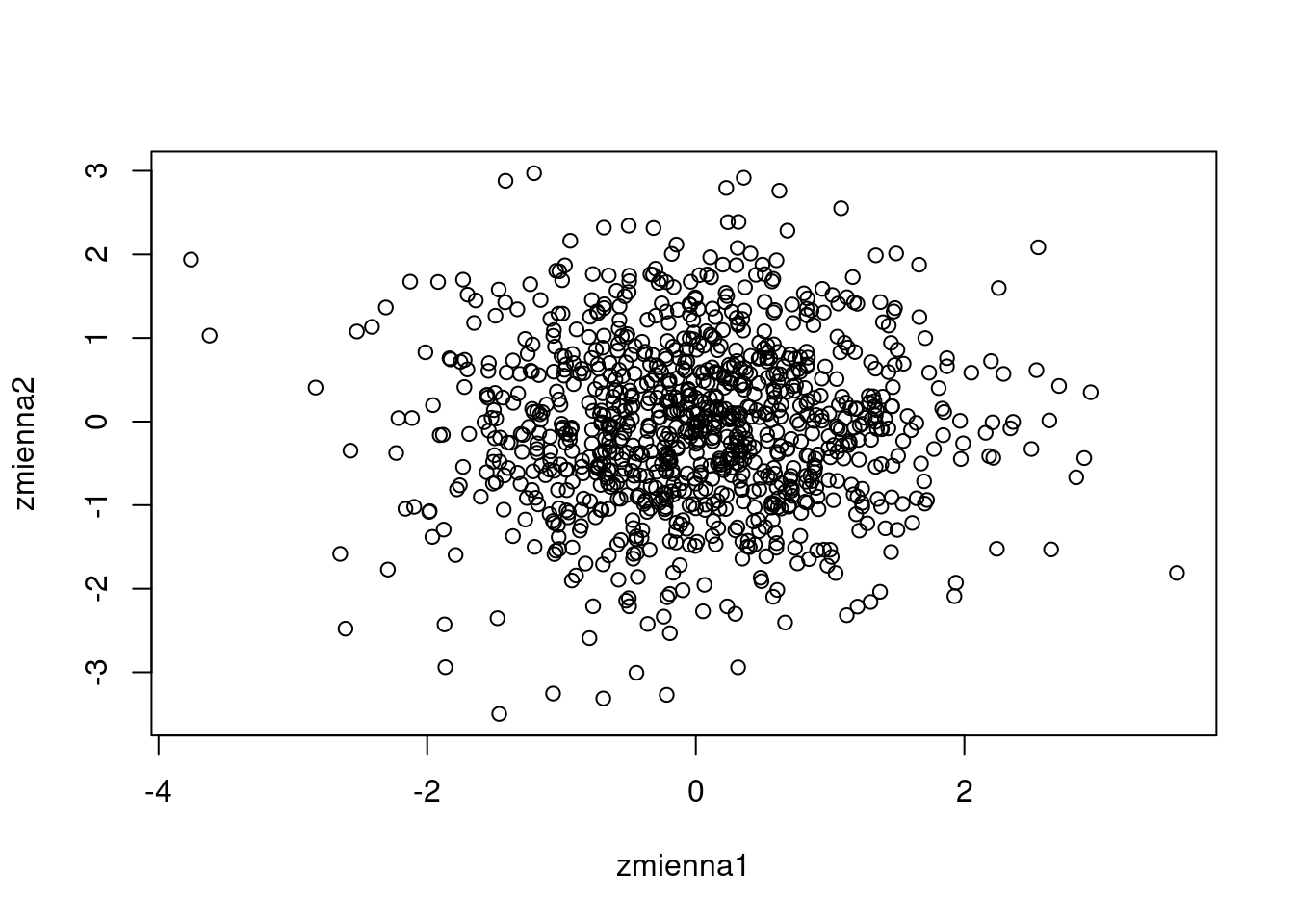
![]()
Problem do rozwiązania: detekcja obserwacji odstających (outliers).
Słowa kluczowe: z-score, IQR (zasada Tukey’a), odległość Mahalanobis’a, isolation forest
Obserwacje odstające (ang. outliers) to wartości znacznie odbiegające od reszty danych. Mogą wskazywać na błędy pomiarowe, nietypowe zdarzenia lub interesujące zjawiska. Niemniej jednak zazwyczaj zwiastują problemy ze stosowanymi narzędziami (modelami), z poprawną interpretacją wyników oraz późniejszym potencjalnym zastosowaniem aplikacyjnym. Wpływają również na statystyki opisowe i wyniki testów statystycznych.
Ich identyfikacja to kluczowy krok w analizie danych!
Załóżmy, że mamy dwie nieskorelowane ze sobą zmienne o rozkładzie normalnym.
zmienna1 <- rnorm(1000)
zmienna2 <- rnorm(1000)
plot(zmienna1, zmienna2)
Obliczmy i przetestujmy (pod kątem istotności statystycznej) współczynnik korelacji liniowej Pearsona:
cor.test(zmienna1, zmienna2)
Pearson's product-moment correlation
data: zmienna1 and zmienna2
t = 0.33458, df = 998, p-value = 0.738
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.05143655 0.07253576
sample estimates:
cor
0.0105903 Wartość współczynnika korelacji jest bardzo niska (0.0105903) i nieistotna statystycznie… ale właśnie tego oczekiwaliśmy.
Wprowadźmy do naszych zmiennych wartość błędną i o 2 rzędy wielkości większą.
zmienna1[100] <- 100
zmienna2[100] <- 100
plot(zmienna1, zmienna2)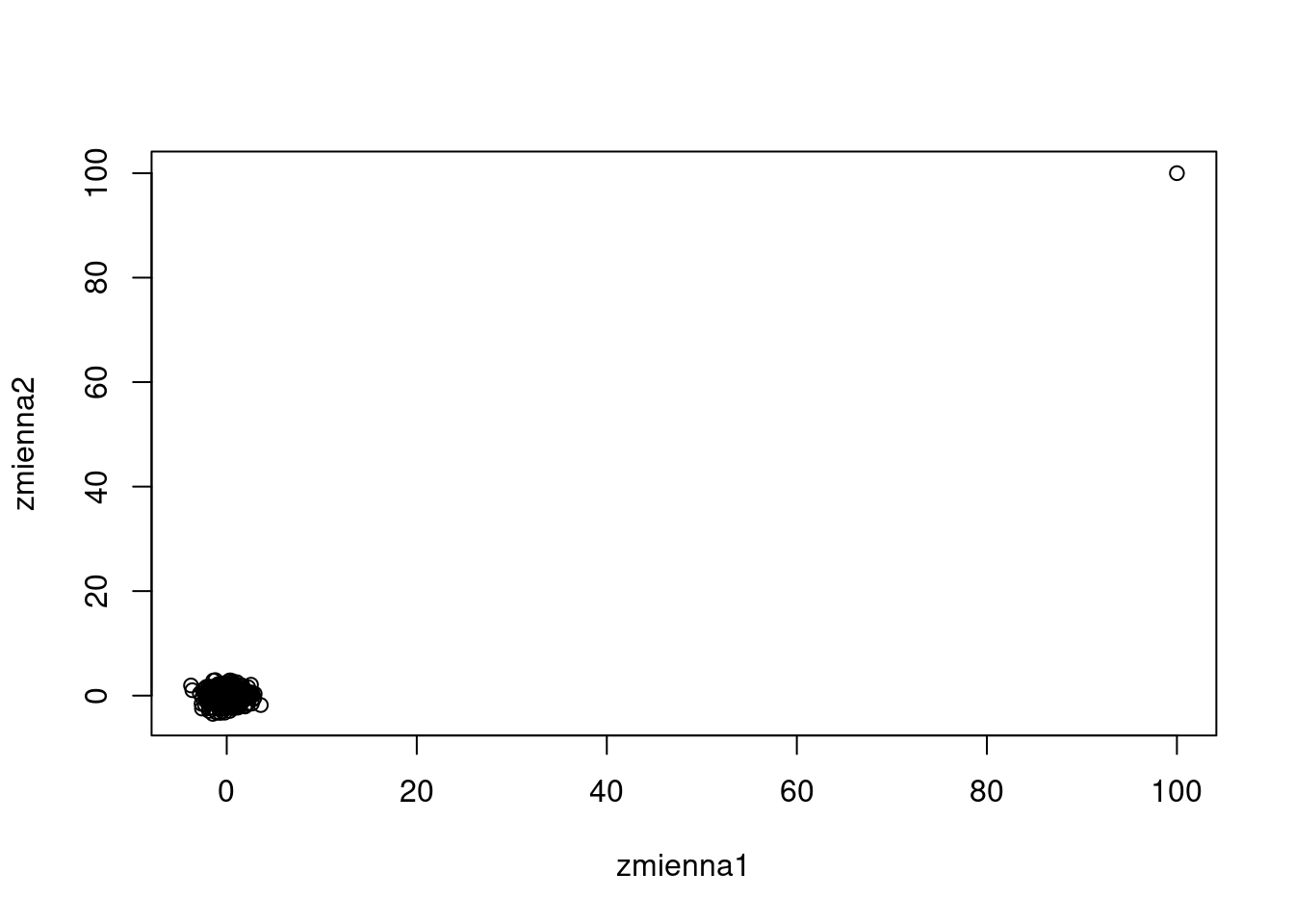
Wartość współczynnika korelacji wynosi obecnie:
cor.test(zmienna1, zmienna2)
Pearson's product-moment correlation
data: zmienna1 and zmienna2
t = 70.311, df = 998, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.9011217 0.9220141
sample estimates:
cor
0.9121586 Jedna obserwacja odstająca (jedna na tysiąc!) całkowicie wypacza wynik. Nie dość, że współczynnik korelacji jest bardzo wysoki (0.9121586) to jest on istotny statystycznie.
Podkreślam, sprawiła to jedna błędna para wartości - jeden promil przypadków.
W takim wypadku współczynnik Spearman’a może nas zazwyczaj uchronić od katastrofy. Poniższe obliczenia potwierdzają tą tezę.
cor.test(zmienna1, zmienna2, method = "spearman")
Spearman's rank correlation rho
data: zmienna1 and zmienna2
S = 163290614, p-value = 0.5222
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.02025534 Decyzja, co zrobić z obserwacjami ewidentnie błędnymi (tzw. błędy grube) jest prosta. Musimy je usunąć, ponieważ wypaczą one wyniki (szczególnie w przypadku metod wariancyjnych).
Obserwacje “podejrzane” (z wartościami mało prawdopodobnymi) stanowią wyzwanie same w sobie, chociażby przez to, że chcąc modelować przebieg procesu, w taki sposób żeby opracowane przez nas narzędzie było w stanie odtworzyć / prognozować wystąpienie wartości z ogonów rozkładów, musimy uwzględnić wartości ekstremalne, czyli takie które niejako z definicji będą pretendentami to oznaczenia jako odstające.
Jeżeli nie posiadamy informacji o procedurach QC (Quality Check) zastosowanych w instytucji, z której dane pochodzą, musimy się im dokładnie przyjrzeć, a na końcu podjąć arbitralna decyzję o ich zatrzymaniu lub usunięciu ze zbioru, za każdym razem szczegółowo opisując naszą procedurę QC i przypadki które zostały pominięte.
Nikt nie mówił, że stosowanie wyrafinowanych narzędzi zwalnia nas z konieczności podejmowania trudnych wyborów. Szczególnie, kiedy nie dysponujemy próbą o rozmiarze tysięcy rekordów i usunięcie każdego rekordu skutkuje zubożeniem materiału, na którym przyszło nam pracować.
W niniejszym poście przedstawiam kilka popularnych metod wykrywania obserwacji odstających w R — od prostych reguł opartych na odchyleniu standardowym, czy IQR po bardziej zaawansowane techniki, jak Isolation Forest, czy też Odległość Mahalanobisa.
Dane wykorzystane w tym poście są danymi wygenerowanymi i obejmują kilka zmiennych o rozkładzie normalnym (zmienne: A oraz B) oraz gamma (zmienna C). Następnie wprowadzono do nich nich obserwacje odstające (błędy grube).
Dane można pobrać TUTAJ
Pierwszym etapem każdej analizy jest identyfikacja wizualna. Obecnie, bardzo często pracujemy na danych zawierających liczbę rekordów niejednokrotnie przekraczających kilkaset tysięcy, co czyni identyfikację obserwacji odstających przez ręczne przeglądanie danych w zasadzie niemożliwą.
Można natomiast zastosować ekstremalnie proste wykresy (jedna linijka kodu), które nam w tym pomogą. Oczywiście pomocna jest w tym świadomość zakresu naturalnej zmienności analizowanej zmiennej. np. wartości ujemne sumy opadów z miejsca możemy oznaczyć jako dane błędne.
Wczytajmy zatem nasze dane
load("data/outliers.rda")str(dane)'data.frame': 200 obs. of 4 variables:
$ A : num 13.11 12.42 7.21 14.52 11.09 ...
$ B : num 4.9 4.38 4.51 5.28 3.6 ...
$ C : num 2.65 1.67 3.49 2.18 2.67 ...
$ LP: int 1 2 3 4 5 6 7 8 9 10 ...Zacznijmy od wykresu dla zmiennej A
ggplot(dane, aes(x = LP, y = A)) +
geom_line()+
theme_bw()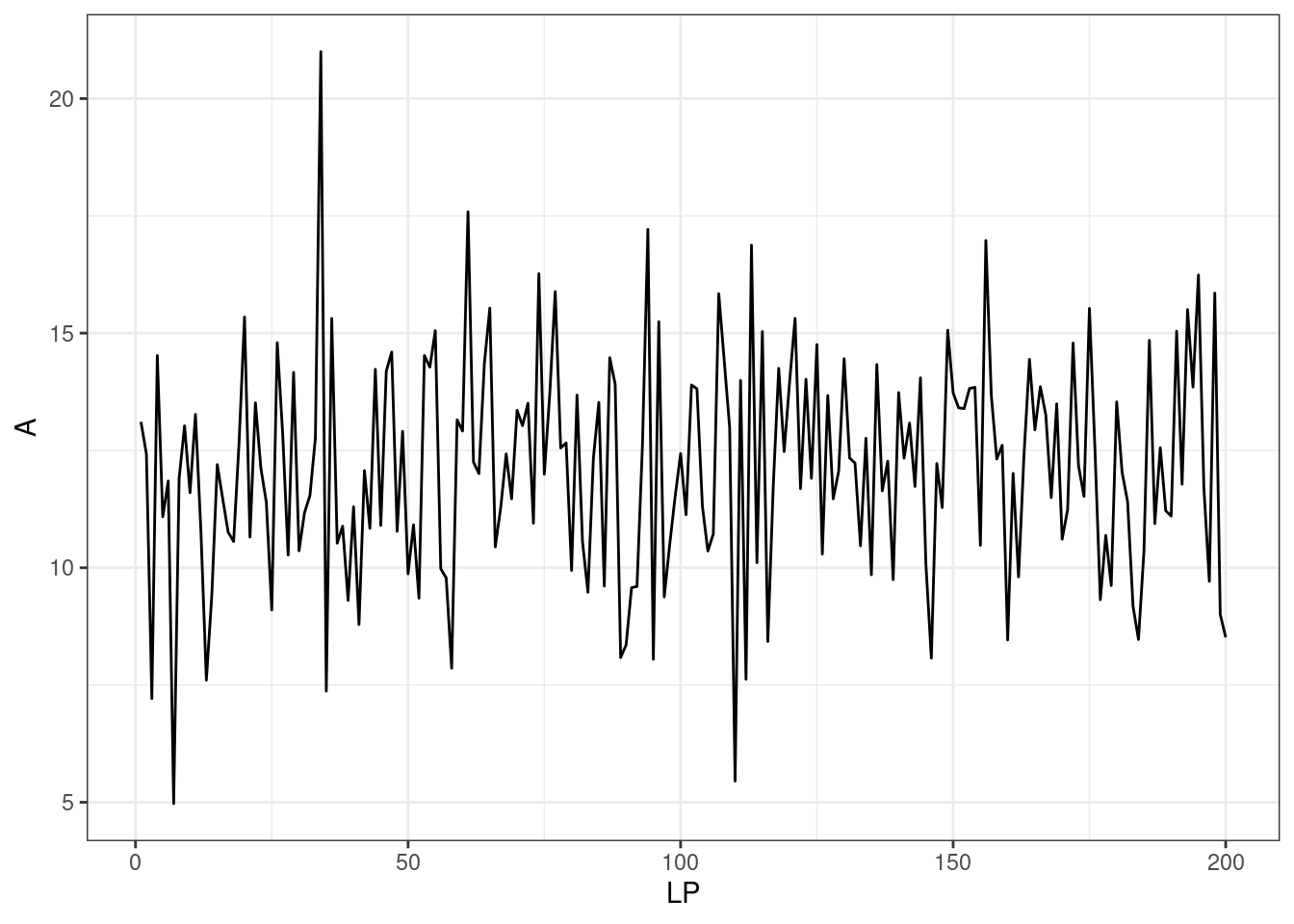
Patrząc na wykres rzucają się w oczy przynajmniej 3 wartości podejrzane. Pierwsza wynosząca około 5 zaraz na początku serii, następnie kolejna przekraczająca 20 w okolicach 30go elementu i jeszcze jedna spadająca ponownie do 5 w pobliżu elementu 110go.
Tutaj mamy zaledwie 200 elementów, ale nawet dla wykresu z 5000 elementów obserwacje odstające będą od razu widoczne. Przykładowo:
seria <- rnorm(5000)
seria[2000] <- 8
plot(seria, type = "l")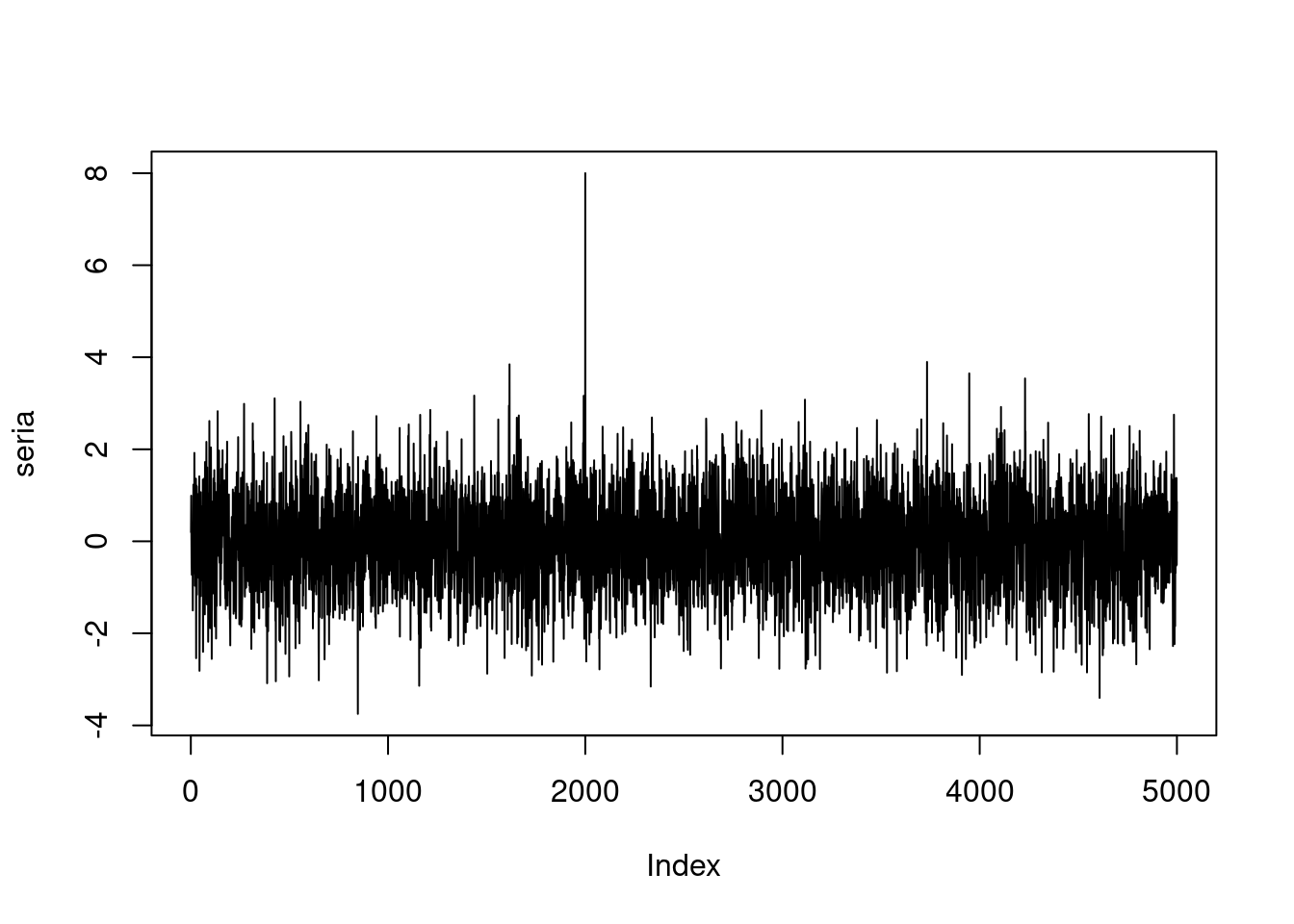
Ewidentnie “wyskakuje” nam wartość 8. Leży ona poza naturalnym zakresem zmienności i jest ona łatwa do zidentyfikowania, a wpisanie tej linii kodu zajmuje jakieś 10s.
Oszczędność czasu, dzięki brakowi konieczności powtarzania całej analizy, obarczonej błędami wynikającymi z pracy na niezweryfikowanych danych, potrafi iść w tygodnie lub nawet miesiące.
Oczywiście analiza wizualna jest tylko wstępem do poczynań bardziej formalnych. Istnieje przynajmniej kilka sposobów identyfikacji obserwacji odstających. Każdy z nich ma wady i zalety, które omówimy poniżej:
oto wybrane metody, które zastosujemy:
IQR
Z-score
Odległość Mahalanobisa
LOF (Local Outlier Factor) - paczka DMwR
Isolation Forest - paczka isotree
Bardzo prosta metoda opierająca się na wartościach rozstępu międzykwartylowego (IQR - Inter Quartile Range), czyli różnicy między Q3 (kwartyl trzeci) a Q1 (kwartyl pierwszy).
Jeżeli wartości zmiennej przekraczają wartości:
Q3+1,5 IQR (w górę)
Q1-1,5 IQR (w dół)
należy te obserwacje uznać jako odstające.
Napiszmy funkcję wykryj_odstajace_iqr.
Jej jedynym argumentem jest wektor wartości, który chcemy testować
wykryj_odstajace_iqr <- function(x) {
q1 <- quantile(x, 0.25, na.rm = TRUE)
q3 <- quantile(x, 0.75, na.rm = TRUE)
iqr <- q3 - q1
dolne <- q1 - 1.5 * iqr
gorne <- q3 + 1.5 * iqr
which(x < dolne | x > gorne)
}Zastosujmy naszą funkcję do zmiennej A z ramki danych dane
wykryj_odstajace_iqr(dane$A)[1] 7 34 110Obserwacje: 7, 34 oraz 110 zostały zidentyfikowane jako odstające.
Zapiszmy ten wektor jako indeks obserwacji odstających
index_out <- wykryj_odstajace_iqr(dane$A)A następnie wykreślmy poprzedni wykres i zaznaczmy nasze obserwacje odstające na czerwono.
ggplot(dane, aes(x = LP, y = A))+
geom_line()+
geom_point(data = dane[index_out, ], color = "red")+
theme_bw()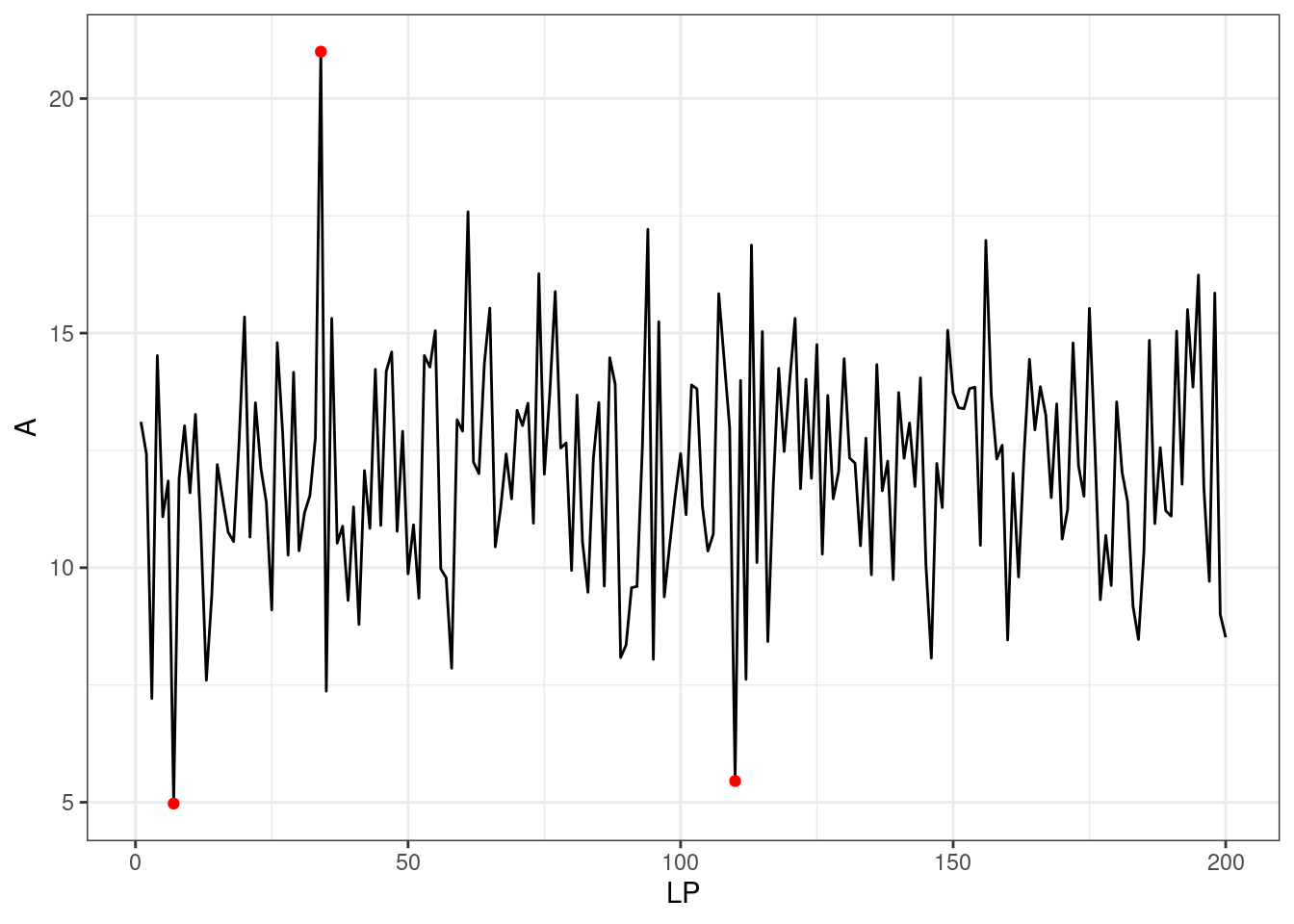
Kolejną metodą jest Z-score, która opiera się na założeniu normalności rozkładu. Wszystkie wartości, które wykraczają poza arbitralnie zdefiniowany przedział (zazwyczaj \(\mu \pm 3\sigma\)), określane są jako odstające/podejrzane.
W rozkładzie normalnym prawdopodobieństwo wystąpienia wartości z przedziału \(\mu \pm 3\sigma\) wynosi 99,7%. Tak więc wartości wykraczające poza niego są bardzo mało prawdopodobne, co predysponuje je to zakwalifikowana jako odstające.
Ponownie napiszmy funkcję wykrywającą takie przypadki.
wykryj_odstajace_z <- function(x, threshold = 3) {
z_scores <- scale(x)
which(abs(z_scores) > threshold)
}Zwróćmy uwagę, że nasza funkcja ma dwa argumenty: x (wektor wartości) oraz threshold (domyślnie przyjmuje on wartość 3, ale można ja samemu zmienić).
Zabieramy się zatem za wykrywanie. Zapiszmy wynik zastosowania funkcji od razu jako indeks z położeniem obserwacji odstających.
Wzięcie całości wyrażenia w nawias spowoduje nie tylko stworzenie obiektu index_out w środowisku globalnym ale również wyświetlenie wyniku w konsoli. Czasami jest to przydatny trik.
(index_out <- wykryj_odstajace_z(dane$A))[1] 7 34Wykres wygląda następująco:
ggplot(dane, aes(x = LP, y = A))+
geom_line()+
geom_point(data = dane[index_out, ], color = "red")+
theme_bw()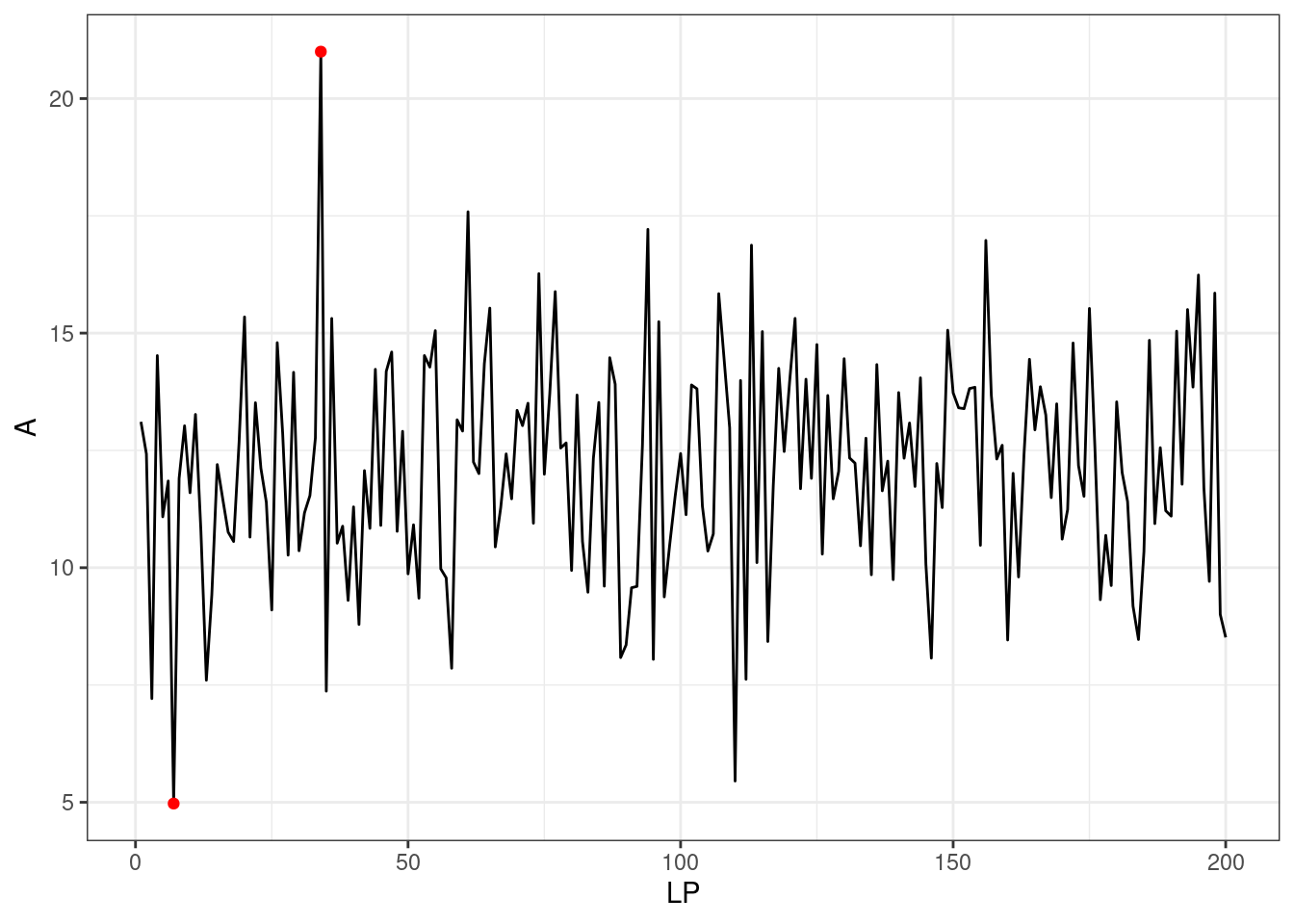
Odległość Mahalanobisa to metoda wykrywania obserwacji odstających w danych wielowymiarowych, która uwzględnia korelacje między zmiennymi i zróżnicowane skale wartości. W przeciwieństwie do klasycznej odległości euklidesowej, Mahalanobis „normalizuje” dane i analizuje je względem ich rozrzutu.
Intuicja podpowiada, że punkt oddalony od centrum danych (średniej) może być uznany za obserwacje odstającą, jeśli jego odległość Mahalanobisa jest duża. Miara ta uwzględnia kształt chmury punktów: “wydłużenia” i korelacje między cechami.
Procedura detekcji:
Obliczamy odległość Mahalanobisa dla każdego punktu w wielowymiarowej przestrzeni.
Ustalamy próg odcięcia na podstawie rozkładu chi-kwadrat:
Punkty dla których wartości odległości są większe niż 97,5% kwantyl rozkładu \(chi^2\) o liczbie stopni swobody odpowiadającej liczbie zmiennych można uznać za obserwacje odstające.
Na początku, załóżmy, że interesują nas tylko zmienne A oraz C z naszej ramki danych. Będzie to łatwiej pokazać na wykresie w dwóch wymiarach, aczkolwiek w rzeczywistych analizach nie musimy się do tego ograniczać.
Argumenty naszej funkcji to df - ramka danych oraz threshold - wartość dystrybuanty rozkładu \(chi^2\) którą uznajemy za wystarczającą. Ponieważ stosujemy tutaj test dwustronny, to wartość krytyczna (przy 5% poziomie istotności) będzie miała prawdopodobieństwo wystąpienia mniejsze niż 0,025, co przekładając na wartości dystrybuanty daje wartość 0,975.
wykryj_odstające_mah <- function(df, threshold = 0.975) {
d2 <- mahalanobis(df, colMeans(df), cov(df))
cutoff <- qchisq(threshold, df = ncol(df))
which(d2 > cutoff)
}(index_out <- wykryj_odstające_mah(dane[ , c("A","B")]) )[1] 7 24 34 65 94 110Na wykresie rozrzutu wygląda to następująco:
ggplot(dane, aes(x = A, y = B))+
geom_point()+
geom_point(data = dane[index_out, ], color = "red")+
theme_bw()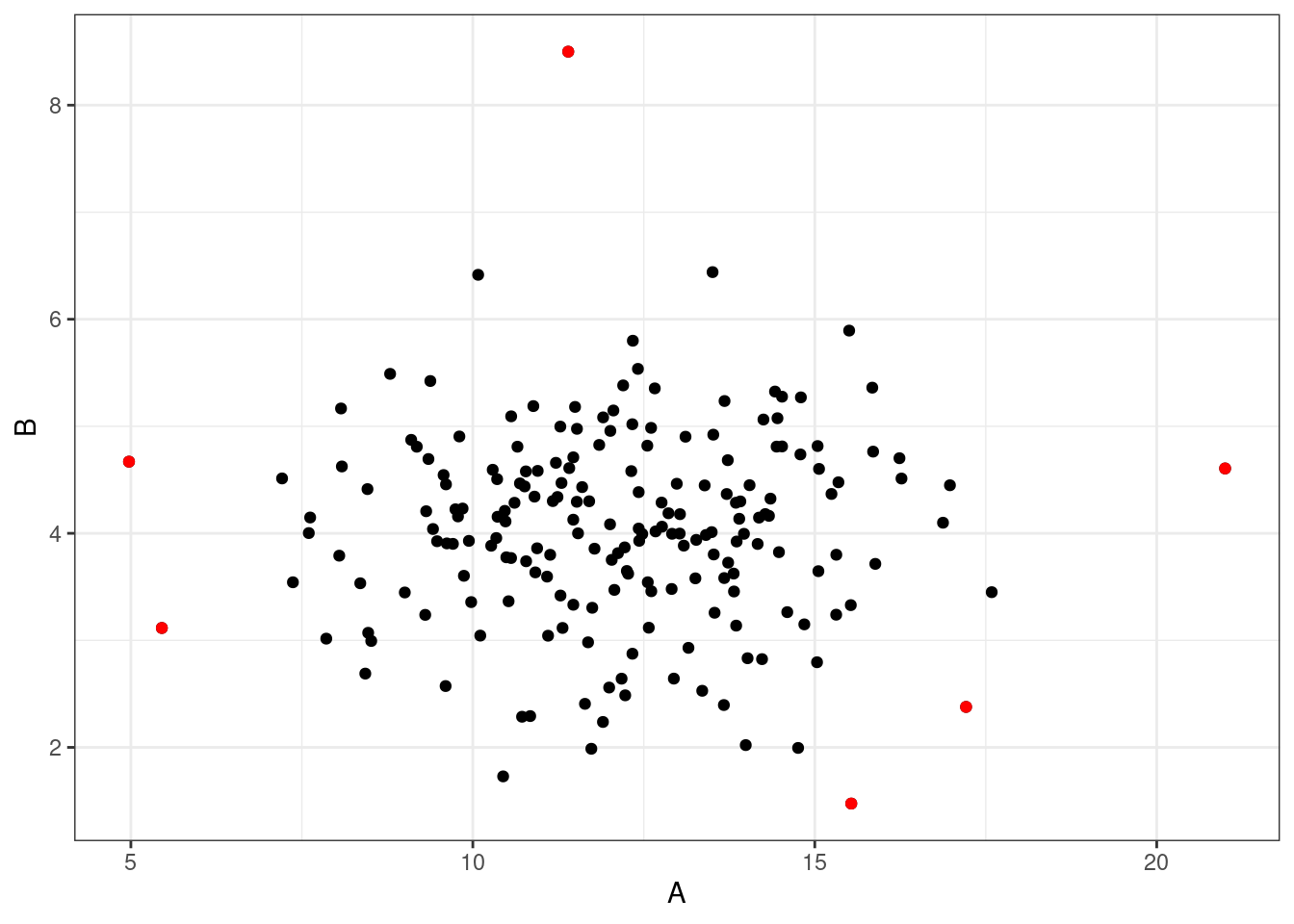
lub ze zmiennymi A i C (zmienna C ma rozkład gamma, więc jest prawo-skośna i może być np. utożsamiana z dobowymi sumami opadu).
(index_out <- wykryj_odstające_mah(dane[ , c("A","C")]) )[1] 7 24 34 81 87 93 110 199ggplot(dane, aes(x = A, y = C))+
geom_point()+
geom_point(data = dane[index_out, ], color = "red")+
theme_bw()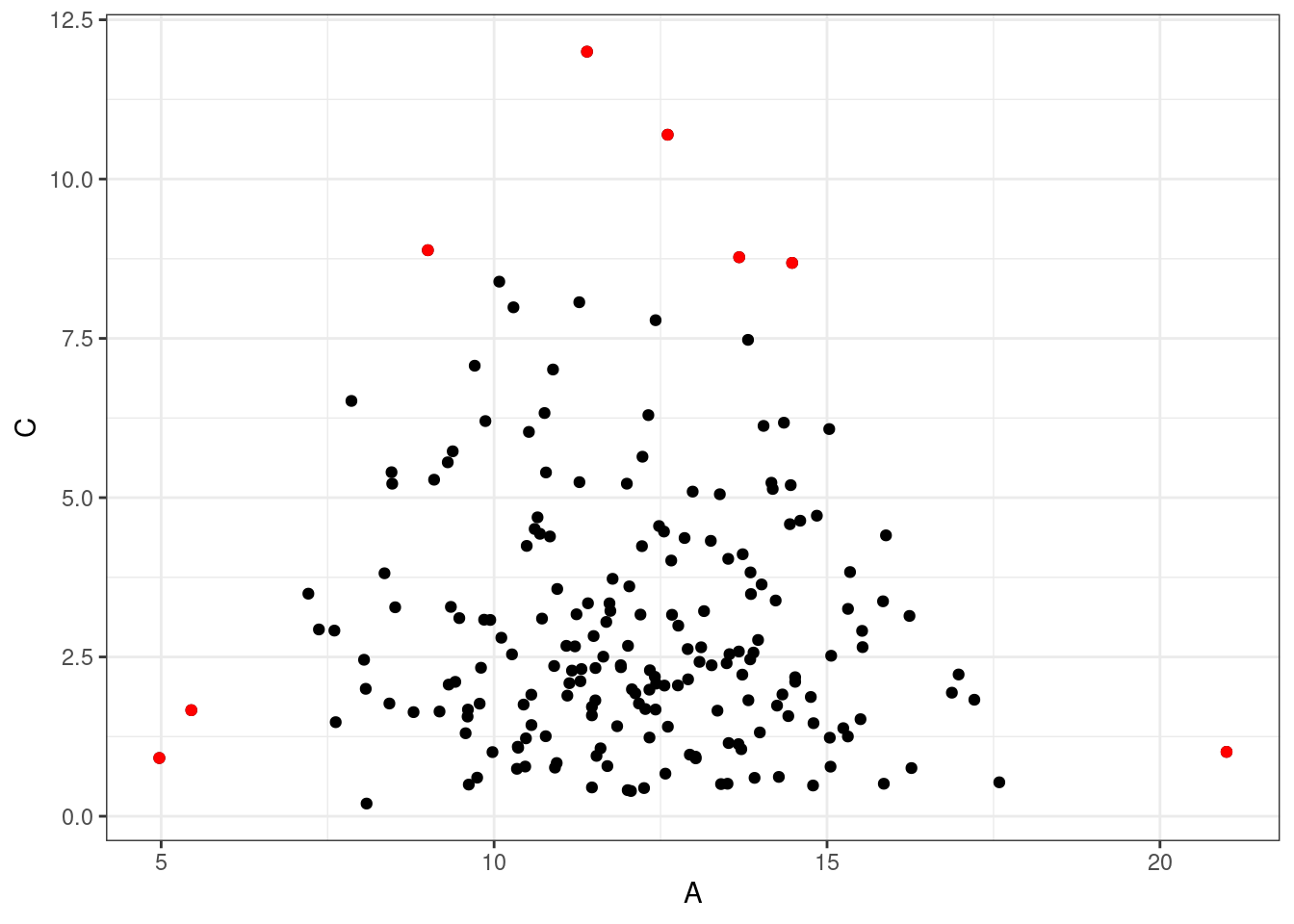
i finalnie dla wszystkich zmiennych:
(index_out <- wykryj_odstające_mah(dane[ , c("A", "B", "C")]) )[1] 7 24 34 65 72 93 110 145 199colors <- rep("navy", length(dane$LP)) #definiujemy podstawowy kolor
colors[index_out] <- "red" # zmieniamy kolor na czerwony według indeksu index_out
library(plotly)
plot_ly(
dane,
x = ~A, y = ~B, z = ~C,
type = "scatter3d",
mode = "markers",
marker = list(color = colors, size = 4, opacity = 0.5)
)Wykres jest interaktywny, więc możemy nasze dane całkiem rozsądnie obejrzeć. (najedź kursorem na wykres, wciśnij lewy przycisk myszki, ruszaj myszką w celu obrócenia wykresu). Dodatkowe możliwości (przesuwania, rotacja, eksport, zoom i ustawienia domyślne widoku) znajdują się w górnym prawym rogu wykresu.
| Zalety: | Wady: |
|---|---|
uwzględnia strukturę współzmienności danych skuteczna w danych wielowymiarowych, szczególnie jeśli mają zależności między cechami |
zakłada wielowymiarowy rozkład normalny danych wrażliwa na obecność “silnych outlierów”, które mogą zniekształcać macierz kowariancji wymaga wystarczającej liczby obserwacji względem liczby zmiennych |
LOF (Local Outlier Factor) to metoda wykrywania obserwacji odstających oparta na analizie lokalnej gęstości przestrzennej punktów (odwrotność średniej odległości - reachability distance). Umożliwia identyfikację outlier’ów, które są nietypowe w kontekście swojego najbliższego otoczenia, a nie całego zbioru danych.
Zasada działania LOF
Dla każdej obserwacji obliczana jest gęstość lokalna, czyli to jak „gęsto” otoczona jest ona przez sąsiadów (zwykle k najbliższych).
Porównuje się gęstość danej obserwacji z gęstością jej sąsiadów.
Jeżeli punkt ma znacznie mniejszą gęstość niż jego otoczenie – uznawany jest za outlier.
Intuicyjnie, punkt wewnątrz zwartej grupy ma podobną gęstość jak sąsiedzi LOF ≈ 1, natomiast punkt odizolowany ma LOF > 1, np. LOF > 1.5, co wskazuje potencjalnego outliera.
library(DMwR2)Registered S3 method overwritten by 'quantmod':
method from
as.zoo.data.frame zoo # Obliczanie LOF dla liczby sąsiadów k = 5
lof_scores <- lofactor(dane[, 1:3], k = 5)
# Obserwacje z wysokim LOF (>1.5)
(index_out <- which(lof_scores > 1.5) )[1] 7 24 34 72 89 110Wykres wygląda następująco:
colors <- rep("navy", length(dane$LP)) #definiujemy podstawowy kolor
colors[index_out] <- "red" # zmieniamy kolor na czerwony według indeksu index_out
library(plotly)
plot_ly(
dane,
x = ~A, y = ~B, z = ~C,
type = "scatter3d",
mode = "markers",
marker = list(color = colors, size = 4, opacity = 0.5)
)| Zalety: | Wady: |
|---|---|
umożliwia wykrycie lokalnych outlierów (np. na granicy klas) nie wymaga założeń odnośnie rozkładu zmiennych dobrze działa dla danych nieliniowych |
wymaga doboru parametru k (liczba sąsiadów) może być wolniejszy przy dużych zbiorach danych |
Isolation Forest (las izolacyjny) to algorytm do wykrywania obserwacji odstających oparty na zupełnie innej idei, niż tradycyjne metody.
Zakłada, że obserwacje odstające są łatwiejsze do odizolowania od pozostałych.
Założenia:
dane dzielone są rekurencyjnie przy pomocy losowych podziałów (jak w drzewach decyzyjnych),
obserwacje, które można odizolować za pomocą mniejszej liczby podziałów, są bardziej “podejrzane” o bycie odstającymi,
im krótsza ścieżka w drzewie prowadzi do danego punktu, tym większe prawdopodobieństwo, że jest to outlier.
Procedura (w skrócie):
tworzymy wiele drzew decyzyjnych, zbudowanych na podstawie losowych prób danych,
w każdym drzewie losowo wybierana jest cecha i punkt podziału,
podział trwa, aż obserwacje zostaną odizolowane (każdy punkt tworzy osobny liść),
dla każdej obserwacji obliczana jest średnia długość ścieżki z wielu drzew,
obserwacje z krótką średnią ścieżką są traktowane jako odstające.
Poniżej przykład z wartością domyślną liczby drzew (500)
library(isotree)
model <- isolation.forest(dane[ , 1:3])
scores <- predict(model, dane[ , 1:3], type = "score")
index_out <- which(scores > quantile(scores, 0.95))I wykres
colors <- rep("navy", length(dane$LP)) #definiujemy podstawowy kolor
colors[index_out] <- "red" # zmieniamy kolor na czerwony według indeksu index_out
library(plotly)
plot_ly(
dane,
x = ~A, y = ~B, z = ~C,
type = "scatter3d",
mode = "markers",
marker = list(color = colors, size = 4, opacity = 0.5)
)| Zalety | Wady |
|---|---|
szybki i skalowalny do dużych zbiorów danych nie zakłada rozkładu danych (nieparametryczny) działa w przestrzeniach wielowymiarowych wykrywa outlier’y o nietypowej strukturze |
wymaga strojenia parametrów (np. próg, liczba drzew) mniej interpretowalna niż metody klasyczne potrzebuje przekształcenia danych kategorycznych (np. kodowanie) |
Warto zaznaczyć, że powyższe metody dają nieco odmienne wyniki - każda z nich bazuje na innych założeniach.
Powyższe przykłady nie wyczerpują bynajmniej zestawu metod, które mogą być zastosowane w praktyce analitycznej, aczkolwiek już ten krótki przegląd pokazuje, jak wiele procedur identyfikacji obserwacji odstających, można stosunkowo łatwo zaimplementować w R i wdrożyć do codziennej praktyki w trakcie przygotowywania danych do dalszych analiz.
Po więcej usystematyzowanych informacji zapraszamy na kursy DataCraft LAB.