# Załaduj biblioteki
library(mlbench)
library(caret)
library(pROC)
library(rms)
library(ggplot2)
library(dplyr)7 Regresja logistyczna
Problem do rozwiązania: modelowanie występowania zjawisk ekstremalnych np. przekroczeń dobowych norm wartości stężenia PM10.
Słowa kluczowe: regresja logistyczna, confusion matrix, ROC, AUC, metryki jakości modeli
7.1 Dane
Baza danych dotyczy stężeń PM10 na stacji przy ulicy Porębskiego w Gdyni. Opisano je tutaj: Section 6.1.
Dane można pobrać tutaj.
7.2 Regresja logistyczna
Załadujmy biblioteki
i dane
load("data/final_daily.rda")summary(final_daily) DATE YEAR MONTH DAY
Min. :2013-01-01 Min. :2013 Min. : 1.000 Min. : 1.00
1st Qu.:2016-01-01 1st Qu.:2016 1st Qu.: 4.000 1st Qu.: 8.00
Median :2019-01-01 Median :2019 Median : 7.000 Median :16.00
Mean :2019-01-01 Mean :2019 Mean : 6.523 Mean :15.73
3rd Qu.:2021-12-31 3rd Qu.:2022 3rd Qu.:10.000 3rd Qu.:23.00
Max. :2024-12-31 Max. :2024 Max. :12.000 Max. :31.00
TMIN TMAX T2M PM10
Min. :-14.263 Min. :-11.070 Min. :-12.484 Min. : 3.227
1st Qu.: 1.392 1st Qu.: 5.213 1st Qu.: 3.477 1st Qu.: 9.729
Median : 5.972 Median : 11.372 Median : 8.741 Median : 14.260
Mean : 6.365 Mean : 11.573 Mean : 9.087 Mean : 17.624
3rd Qu.: 12.017 3rd Qu.: 18.169 3rd Qu.: 15.385 3rd Qu.: 22.095
Max. : 21.476 Max. : 30.427 Max. : 25.586 Max. :112.271
NA's :1162
TP MSL D2M U10
Min. : 0.00000 Min. : 972.2 Min. :-14.4959 Min. :-9.929
1st Qu.: 0.06437 1st Qu.:1009.3 1st Qu.: 0.9262 1st Qu.:-1.351
Median : 0.61083 Median :1015.1 Median : 5.5154 Median : 1.440
Mean : 2.12145 Mean :1014.8 Mean : 5.8156 Mean : 1.393
3rd Qu.: 2.70629 3rd Qu.:1020.8 3rd Qu.: 11.3634 3rd Qu.: 4.012
Max. :54.22163 Max. :1046.4 Max. : 21.1175 Max. :12.875
V10 VEL10
Min. :-11.4394 Min. : 1.023
1st Qu.: -1.3818 1st Qu.: 3.527
Median : 0.6145 Median : 4.721
Mean : 0.6121 Mean : 4.956
3rd Qu.: 2.7275 3rd Qu.: 6.122
Max. : 10.0851 Max. :13.967
7.3 Przygotowanie danych wejściowych i podział na ciąg uczący i testujący
Zapiszmy otwartą przed chwilą ramkę jako dane usuwając przy okazji przypadki z brakującymi danymi PM10 (jedyna zmienna gdzie występują, dlatego zastosujemy proste filtrowanie a nie funkcja complete_cases).
dane <- final_daily %>%
filter(!is.na(PM10))
rm(final_daily)W badaniach (Czernecki, Marosz, and Jędruszkiewicz 2021) wskazują na istnienie autokorelacji dobowych wartości PM10, dlatego dodamy do naszych danych przesunięte o 1 i 2 dni ciągi PM10, które pozwolą modelowi na “pozyskanie” informacji odnośnie średniodobowych stężeń PM10 w dwóch dniach poprzedzających krok dla którego wykonujemy modelowanie. Nie jest to standardowa praktyka. Za każdym razem powinna być poprzedzona analizą autokorelacji.
dane <- dane %>%
mutate(PM10_lag1 = lag(PM10, n = 1),
PM10_lag2 = lag(PM10, n = 2))Ze względu na fakt, że dodanie przesuniętych w czasie (o jeden i dwa dni) danych generuje NA dla pierwszych kroków czasowych nowych zmiennych, jesteśmy zmuszeni ponownie wyczyścić dane z NA. Usuńmy zatem niekompletne przypadki, żeby nie trzeba było o tym pamiętać później - niektóre funkcje stosowanych bibliotek mogą być, powiedzmy delikatnie, wrażliwe na braki danych.
dane <- dane %>%
filter(!is.na(PM10_lag1)) %>%
filter(!is.na(PM10_lag2))Stwórzmy następnie zmienną PM10_ex, która będzie przyjmować wartości 1 kiedy średnia dobowa wartość stężenia PM10 przekroczy wartość 30\(\mu \text{g/m}^3\). Zmniejszenie ustawowego limitu (50\(\mu \text{g/m}^3\)) uzasadniono tutaj Section 6.1. Usuniemy następnie zmienną PM10 - nie będzie już potrzebna. Będziemy modelować jedynie wystąpienie przekroczenia.
dane <- dane %>%
mutate(PM10_ex = if_else(PM10 > 30, 1, 0)) %>%
dplyr::select(-PM10)Załóżmy, że będziemy kalibrować model dla wybranych miesięcy (grudzień:marzec) i usuniemy zmienne związane z czasem: DATE, YEAR, MONTH, DAY. Podczas kalibracji i oceny modelu nie będziemy ich potrzebować.
Przy czym, jeżeli chcielibyśmy na jakimś etapie procedury badawczej analizować konkretne epizody smogowe, to wówczas nie należy ich usuwać, przy czym wyłączamy je z predyktorów modelu podczas kalibracji, zapisując odpowiednią formułę definiującą nasz model.
Wybierzemy zatem nasz zakres czasowy i usuńmy niepotrzebne zmienne.
dane <- dane %>%
filter(MONTH %in% c(12, 1, 2, 3)) %>%
dplyr::select(-DATE, -YEAR, -MONTH, -DAY)Tworzymy ramki danych do kalibracji (train) i ewaluacji modelu (test) w proporcji 7 do 3, a następnie usuwamy ramkę dane i wektor index.
set.seed(123)
index <- createDataPartition(dane$PM10_ex, p = 0.7, list = FALSE)
train <- dane[index, ]
test <- dane[-index, ]
rm(dane, index)7.4 Regresja logistyczna
Model regresji logistycznej tworzymy, wykorzystując funkcję glm(). Wartość argumentu family ustawiamy na binomial.
Skalibrujmy model na ciągu kalibracyjnym train.
model_train <- glm(PM10_ex ~ .,
data = train,
family = "binomial")
summary(model_train)
Call:
glm(formula = PM10_ex ~ ., family = "binomial", data = train)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -18.29262 14.53677 -1.258 0.20826
TMIN 0.25993 0.23963 1.085 0.27805
TMAX 0.56241 0.24786 2.269 0.02327 *
T2M -1.09003 0.47943 -2.274 0.02299 *
TP -0.08462 0.08944 -0.946 0.34409
MSL 0.01755 0.01433 1.224 0.22081
D2M 0.19665 0.12876 1.527 0.12668
U10 -0.19100 0.06261 -3.051 0.00228 **
V10 0.99493 0.13926 7.144 9.05e-13 ***
VEL10 -1.30201 0.18400 -7.076 1.48e-12 ***
PM10_lag1 0.10169 0.01465 6.940 3.91e-12 ***
PM10_lag2 0.01428 0.01170 1.221 0.22223
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 742.65 on 750 degrees of freedom
Residual deviance: 292.32 on 739 degrees of freedom
AIC: 316.32
Number of Fisher Scoring iterations: 8Na podstawie opracowanego modelu (obiekt model_train), z wykorzystaniem funkcji predict() prognozujemy serię prawdopodobieństw wystąpienia zdarzenia PM_10 powyżej 30\(\mu \text{g/m}^3\).
Otrzymując prawdopodobieństwo (wymuszamy to wartością “response” argumentu type) jako rezultat, musimy podjąć decyzję odnośnie progu wartości, który uznamy za wystarczający aby założyć wystąpienie zdarzenia. Intuicyjnie wartość 0,5 jest bardzo pociągająca. Niekoniecznie właściwa, ale na pewno pociągająca. Od niej zaczniemy.
# Predykcja prawdopodobieństwa wystąpienia zdarzenia
pred_prob_train <- predict(model_train,
newdata = train,
type = "response")
# ustalamy arbitralnie prawdopodobieństo na 0,5 i dokonujemy
# reklasyfikacji naszej serii pradopodobieństw na zmienna binarną
pred_class_train <- ifelse(pred_prob_train > 0.5, 1, 0)Następnie porównujemy rzeczywiste wystąpienia zjawiska z prognozowanymi przez model - tworzymy tzw. macierz pomyłek (confusion matrix). Funkcja confusionMatrix() pochodzi z pakietu caret i jako wejście potrzebuje wektorów typu czynnik (factor), więc “w locie” dokonujemy tej konwersji.
confusionMatrix(data = as.factor(pred_class_train),
reference = as.factor(train$PM10_ex),
positive = "1")Confusion Matrix and Statistics
Reference
Prediction 0 1
0 581 35
1 23 112
Accuracy : 0.9228
95% CI : (0.9013, 0.9408)
No Information Rate : 0.8043
P-Value [Acc > NIR] : <2e-16
Kappa : 0.7469
Mcnemar's Test P-Value : 0.1486
Sensitivity : 0.7619
Specificity : 0.9619
Pos Pred Value : 0.8296
Neg Pred Value : 0.9432
Prevalence : 0.1957
Detection Rate : 0.1491
Detection Prevalence : 0.1798
Balanced Accuracy : 0.8619
'Positive' Class : 1
7.4.1 Wybrane metryki jakości
Wytrenowaliśmy model i poddaliśmy ocenie jego jakość z wykorzystaniem macierzy pomyłek.
Jak widać, na domyślnym “wyjściu” z funkcji glm(), pojawia znaczna liczba metryk, które można wykorzystać w analizie jakości modelu. Poniżej omówię wybrane z nich. Ich znajomość jest niezbędna w przypadku oceny jakości modeli klasyfikacyjnych. Niestety w ich obfitym uniwersum panuje spory bałagan. Szczegółowy opis i wzory wykorzystywane w funkcji confusionMatrix() można odszukać w helpie pakietu caret.
Główne źródło zamieszczonych poniżej informacji to strona WWRP/WGNE Joint Working Group on Forecast Verification Research. Polecam uważne jej przeczytanie - zawiera mnóstwo przydatnych informacji, dotyczących ewaluacji modeli.
Zacznijmy od macierzy pomyłek inaczej zwanej confusion matix. Pozostawiam nazewnictwo angielskie, uzupełniając je o funkcjonujące nazwy alternatywne.
Struktura macierzy pomyłek.
| OBSERVED NO | OBSERVED YES | TOTAL | |
| FORECAST NO | CORRECT NEGATIVE (TN - true negative) |
MISSES (FN - false negative) |
FORECAST NO |
| FORECAST YES | FALSE ALARMS (FP - false positive) |
HITS (TP - true positive) |
FORECAST YES |
| TOTAL | OBSERVED NO | OBSERVED YES | TOTAL |
Accuracy
\[ \text{Accuracy} = \frac{HITS+\text{CORRECT NEGATIVES}}{TOTAL} \]
Odpowiada na pytanie: jaki odsetek prognoz był poprawny.
Zakres: 0 do 1,
Idealny model: 1
Opis miary: prosta, intuicyjna. Może być myląca, ponieważ jest silnie uzależniona od najczęściej występującej kategorii, a niedoszacowanie występowania zdarzeń ekstremalnych przez model może znacznie ograniczać jej stosowalność.
Bias score (frequency bias)
\[ \text{BIAS} = \frac{HITS+\text{FALSE ALARMS}}{HITS + MISSES} \]
Odpowiada na pytanie: jak prognozowana częstotliwość zdarzeń „YES” ma się do obserwowanej częstości zdarzeń „YES”?
Zakres: 0 do \(\infty\)
Wartość idealna: 1
Opis miary: mierzy stosunek częstości zdarzeń prognozowanych do częstości zdarzeń obserwowanych. Wskazuje, czy model ma tendencję do niedoszacowania (BIAS<1) lub przeszacowania (BIAS>1) prognozowanych zdarzeń. Nie mierzy stopnia zgodności prognozy z obserwacjami, mierzy jedynie częstości względne.
Probability of detection (POD) - aka H, HIT RATE, SENSITIVITY, RECAL lub TRUE POSITIVE RATE
\[ \text{POD} = \frac{HITS}{HITS + MISSES} \]
Odpowiada na pytanie: jaki odsetek obserwowanych “YES” został poprawnie prognozowany.
Zakres: 0 do 1
Wartość idealna: 1
Opis miary: wrażliwa na liczbę poprawnych prognoz “YES” (HITS - true positives), ale ignoruje fałszywe alarmy. Bardzo wrażliwa na klimatologiczną częstość występowania zdarzenia. Dobra miara w przypadku analizy rzadkich zdarzeń. Powinna być stosowana w połączeniu ze współczynnikiem fałszywych alarmów (FALSE ALARM RATIO). POD jest również składową krzywej ROC, szeroko stosowanej w prognozach probabilistycznych.
Specificity aka TRUE NEGATIVE RATE (1-False Alarm Rate)
\[ \text{Specificity} = \frac{\text{CORRECT NEGATIVE}}{\text{CORRECT NEGATIVE} + \text{FALSE ALARMS}} \]
Odpowiada na pytanie: Jaki odsetek odpowiedzi “NO” był poprawnie prognozowany.
Zakres: 0 do 1
Wartość idealna: 1
False Alarm Ratio (FAR)
\[ \text{FAR} = \frac{\text{FALSE ALARMS}}{HITS + \text{FALSE ALARMS}} \]
Odpowiada na pytanie: jaki odsetek prognozowanych “YES” w rzeczywistości nie wystąpiło (czyli były fałszywymi alarmami)
Zakres: 0 do 1.
Wartość idealna: 1
Opis miary: czuła na fałszywe alarmy, ale ignoruje chybienia. Bardzo czuła na klimatologiczną częstość występowania zdarzenia. Należy ja stosować w połączeniu z prawdopodobieństwem wykrycia (POD).
Probability of false detection aka FALSE ALARM RATE, FALSE POSITIVE RATE, czasami oznaczana również jako F
\[ \text{FALSE ALARM RATE} = \frac{\text{FALSE ALARMS}}{\text{CORRECT NEGATIVES} + \text{FALSE ALARMS}} \]
Odpowiada na pytanie: jaki odsetek obserwowanych “NO” zostało niepoprawnie prognozowanych jako “YES”.
Zakres: 0 do 1
Wartość idealna: 0
Opis miary: wrażliwa na fałszywe alarmy, ale ignoruje chybienia. Nie jest często raportowana w przypadku prognoz deterministycznych, ale stanowi ważny element ROC, szeroko stosowanej w prognozach probabilistycznych.
Success Ratio (SR)
\[ \text{SR} = \frac{\text{HITS}}{\text{HITS} + \text{FALSE ALARMS}} \]
Odpowiada na pytanie: Jaki odsetek prognoz “YES” był poprawny.
Zakres: 0 do 1
Wartość idealna: 1
Opis miary: podaje informacje o prawdopodobieństwie wystąpienia obserwowanego zdarzenia, zakładając, że zostało ono prognozowane. Jest wrażliwa na fałszywe alarmy, ale ignoruje chybienia. SR jest równy 1-FAR.
Threat score (CSI - critical success index)
\[ \text{TS} = \frac{\text{HITS}}{\text{HITS} + MISSES + \text{FALSE ALARMS}} \]
Odpowiada na pytanie: jak dobrze prognoza “YES” koresponduje do obserwowanych zdarzeń “YES”
Zakres: 0 do 1
Wartość idealna: 1
Opis miary: mierzy odsetek obserwowanych i/lub prognozowanych zdarzeń, które zostały prawidłowo przewidziane. Można to rozumieć jako dokładność, gdy true negatives zostaną usunięte z analizy. TS dotyczy tylko prognoz, “które są istotne”. Wrażliwy na trafienia, karze zarówno za chybienia(MISSES), jak i fałszywe alarmy (FALSE ALARMS). Nie rozróżnia źródła błędu prognozy. Zależy od klimatologicznej częstości zdarzeń (gorsze wyniki dla rzadszych zdarzeń), ponieważ niektóre trafienia mogą wystąpić wyłącznie w wyniku przypadku.
Heidke skill score (Cohen’s k) - HSS
\[ \text{HSS} = \frac{(HITS + \text{CORRECT NEGATIVES})-\text{EXPECTED CORRECT}_{random}}{N - \text{EXPECTED CORRECT}_{random}} \]
gdzie:
\[ \text{EXPECTED CORRECT}_{random} = \frac{1}{N}((TP + FN)(TP + FP)+(TN + FN)(TN+FP)) \]
w powyższym wzorze wyjątkowo (ze względów technicznych) posłużyłem się skrócona notacją elementów confusion matrix
Odpowiada na pytanie: Jaka jest dokładność prognozy w porównaniu do prognozy losowej
Zakres: -1 do 1, 0 oznacza brak umiejętności (skill) modelu
Wartość idealna: 1
Opis miary: Mierzy odsetek poprawnych prognoz po wyeliminowaniu prognoz, które byłyby poprawne wyłącznie dzięki przypadkowi. Jest to forma uogólnionego wyniku jakości (tzw. skill modelu), gdzie wynik w liczniku to liczba poprawnych prognoz, a punktem odniesienia w tym przypadku jest prognoza przypadkowa.
7.4.2 Krzywa ROC i AUC
Metryki omówione w poprzednim rozdziale dotyczą macierzy pomyłek, tworzonych już po zastosowaniu określonego progu odcięcia. W celu oceny modelu w pełnym zakresie progów odcięcia należy wykreślić i przeanalizować tzw. krzywą ROC (Receiver Operating Characteristic). Pozwala ona na obliczenie popularnej metryki AUC (area under curve), której wartość wskazuje na ogólną jakość modelu (im bliższa jest 1, tym model lepszy). Dodatkowo z jej wykorzystaniem możemy porównywać modele oraz zoptymalizować wybór progu odcięcia.
Jednym z najszybszych sposób wykreślenia ROC i obliczenia AUC jest wykorzystanie runkcji roc() z pakietu pROC.
roc_obj <- roc(response = train$PM10_ex,
predictor = pred_prob_train)Setting levels: control = 0, case = 1Setting direction: controls < casesplot(roc_obj, col = "blue", main = "ROC Curve")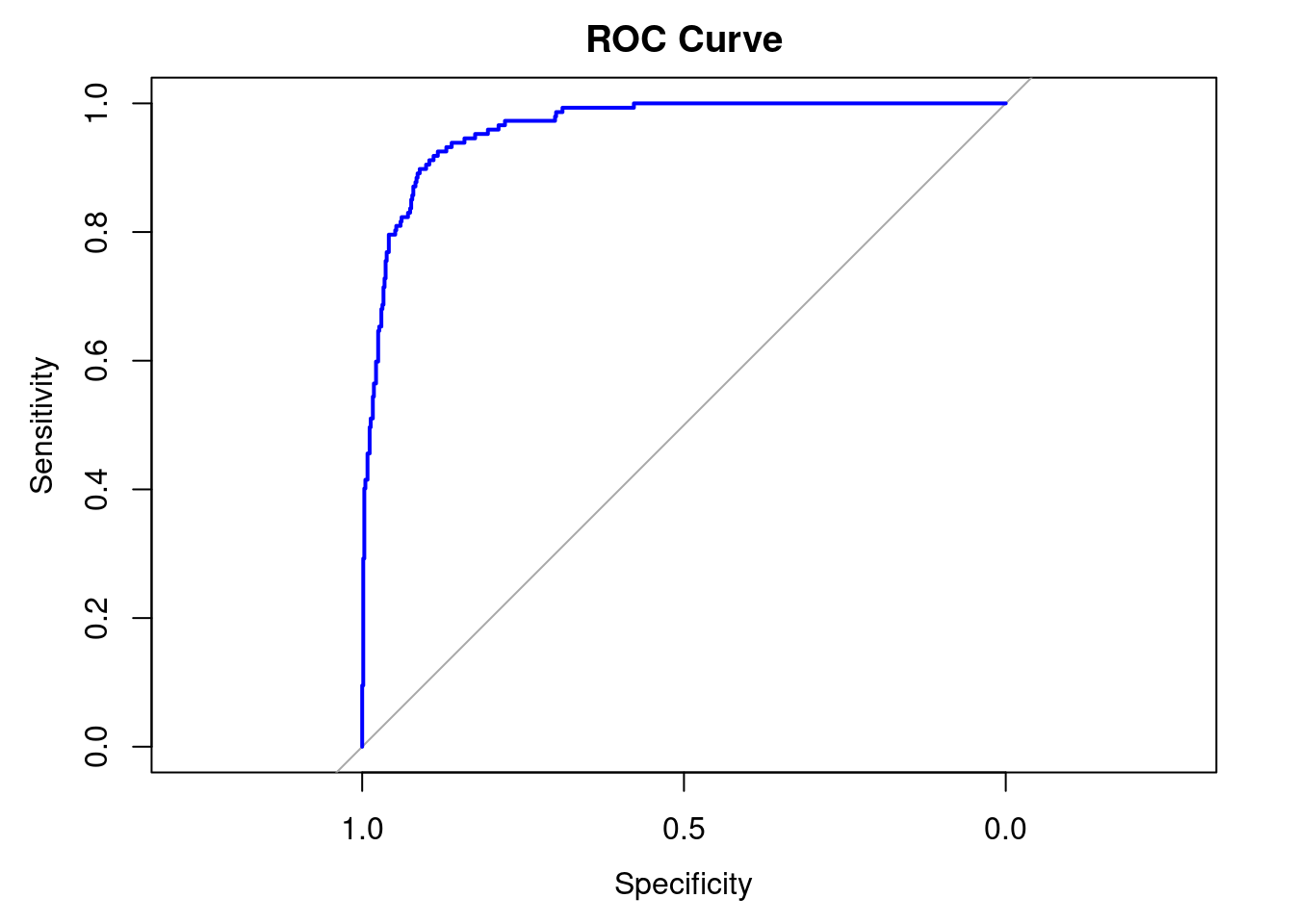
auc(roc_obj)Area under the curve: 0.9623Nie wygląda ona zbyt efektownie, ale aby “na szybko” podejrzeć jej kształt, wystarczy.
Za chwilę wykreślimy ROC jeszcze na dwa sposoby.
Wróćmy do problemu doboru odpowiedniego punktu odcięcia. Prawdopodobieństwo 0,5 mimo, że podpowiadane przez intuicję, nie jest zazwyczaj optymalnym wyborem.
Wystarczy spojrzeć na poniższą ROC (tym razem z pakietu verification, pozwalającego na oznaczenie potencjalnych punktów odcięcia na wykresie).
library(verification)
roc.plot(train$PM10_ex, pred_prob_train,
thresholds = NULL,
binormal = FALSE,
legend = FALSE,
leg.text = NULL,
plot = "emp",
CI = F,
n.boot = 1000, alpha = 0.05, tck = 0.01,
plot.thres = seq(0.1, 0.9, 0.1),
show.thres = TRUE,
main = "ROC Curve",
xlab = "False Alarm Rate",
ylab = "Hit Rate",
extra = FALSE)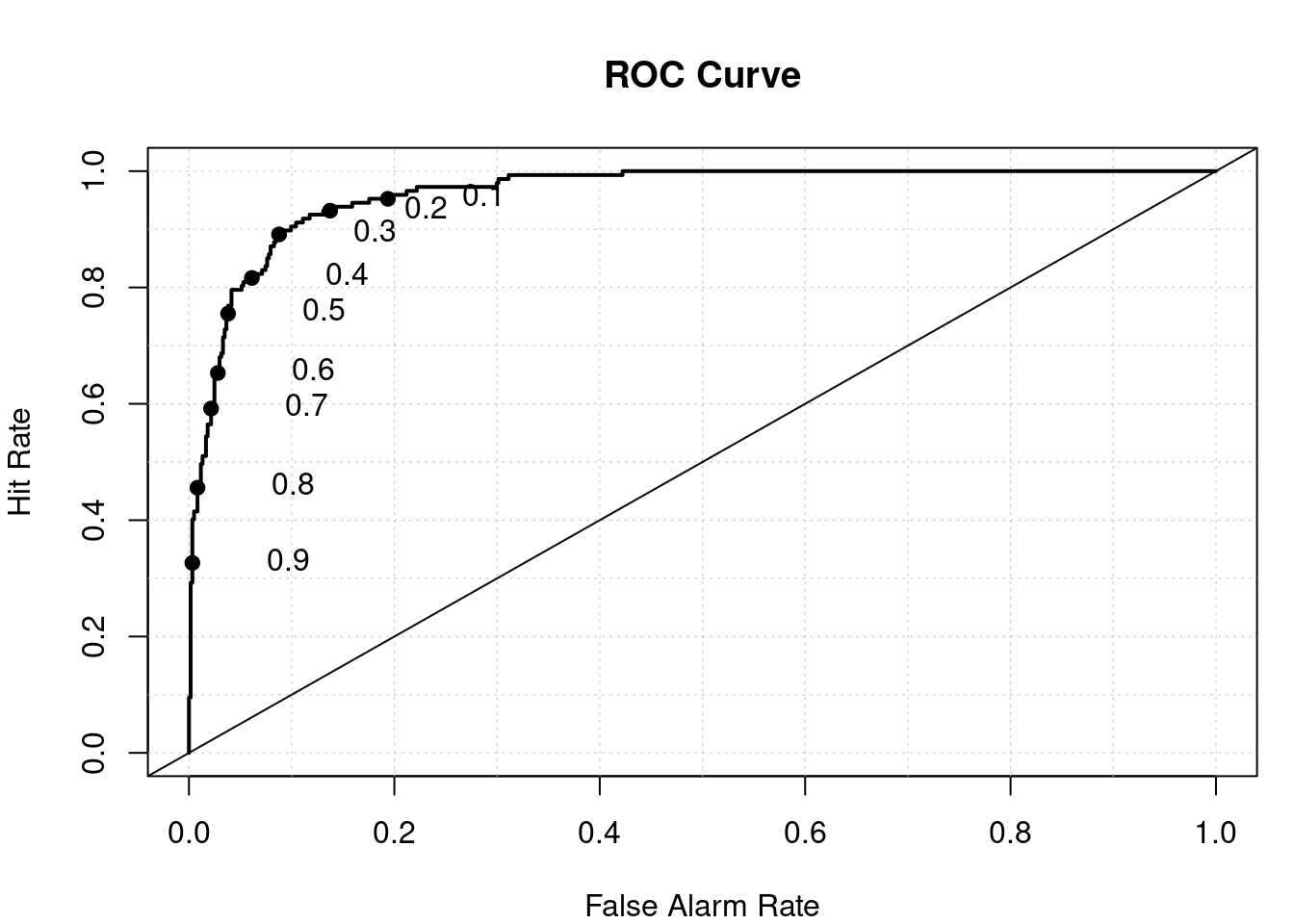
Lepszą wartością progu byłaby wartość między 0,2 a 0,3, ale w jaki sposób to określić.
Tutaj z pomocą przychodzi metoda Youden’a (Ruopp et al. 2008) oparta o indeks J Youden’a (celem jest wybór takiego progu odcięcia, który najlepiej równoważy czułość (Sensitivity) i swoistość (Specificity1), czyli minimalizuje liczbę błędów klasyfikacji), lub identyfikacja punktu najbliższego górnemu lewemu rogowi wykresu, który wyznacza model idealny. Pozwala to na określenie optymalnego wyboru punktu odcięcia. W naszym przypadku posłużymy się metodą Youdena.
library(pROC)
roc_obj <- roc(train$PM10_ex, pred_prob_train)Setting levels: control = 0, case = 1Setting direction: controls < casesopt_cut <- coords(roc_obj,
x = "best",
best.method = "youden",
ret = "threshold")
opt_cut threshold
1 0.2955465#opt_cut[[1]]Teraz przygotowujemy macierz pomyłek z nowym progiem
# Zaczynamy od predykcji klas z wykorzystaniem wektora pred_prob_train
pred_class_youden <- ifelse(pred_prob_train >
opt_cut[[1]], 1, 0)
# Macierz pomyłek
confusionMatrix(data = as.factor(pred_class_youden),
reference = as.factor(train$PM10_ex))Confusion Matrix and Statistics
Reference
Prediction 0 1
0 550 15
1 54 132
Accuracy : 0.9081
95% CI : (0.8852, 0.9278)
No Information Rate : 0.8043
P-Value [Acc > NIR] : 4.188e-15
Kappa : 0.7348
Mcnemar's Test P-Value : 4.770e-06
Sensitivity : 0.9106
Specificity : 0.8980
Pos Pred Value : 0.9735
Neg Pred Value : 0.7097
Prevalence : 0.8043
Detection Rate : 0.7324
Detection Prevalence : 0.7523
Balanced Accuracy : 0.9043
'Positive' Class : 0
Jak widać nastąpił wyraźny wzrost jakości pod kątem wykrywalności. W wersji z nowym progiem aż 132 przypadki przekroczeń stężen PM_10 z łącznie 147 zostały poprawnie zaklasyfikowane (true positives). W przypadku domyślnego progu (0,5) błędów (false negatives) było ponad dwukrotnie więcej (35 przypadków). Wniosek: optymalizacja progu odcięcia działa i znacznie polepsza nasz model pod tym kątem. Niemniej jednak przed nami kolejny kluczowy element analizy - ewaluacja na danych nie biorących udziału w kalibracji, która pozwoli na obiektywną ocenę zdolności generalizacji modelu.
7.5 Ewaluacja na danych testowych
Dokonajmy ewaluacji naszego modelu na danych testowych z wyznaczonym wcześniej optymalnym punktem odcięcia.
# Predykcja prawdopodobieństw oraz klas przekroczenia PM10
# z wykorzytaniem określonego metodą Youden'a progu odcięcia.
pred_prob_test <- predict(model_train, newdata = test, type = "response")
pred_class_test <- ifelse(pred_prob_test > opt_cut[[1]], 1, 0)confusionMatrix(as.factor(pred_class_test),
as.factor(test$PM10_ex))Confusion Matrix and Statistics
Reference
Prediction 0 1
0 234 14
1 28 45
Accuracy : 0.8692
95% CI : (0.8273, 0.904)
No Information Rate : 0.8162
P-Value [Acc > NIR] : 0.00694
Kappa : 0.6006
Mcnemar's Test P-Value : 0.04486
Sensitivity : 0.8931
Specificity : 0.7627
Pos Pred Value : 0.9435
Neg Pred Value : 0.6164
Prevalence : 0.8162
Detection Rate : 0.7290
Detection Prevalence : 0.7726
Balanced Accuracy : 0.8279
'Positive' Class : 0
A teraz porównajmy obie ROC
W tym celu wypreparujemy dane dotyczące Sensitivity oraz Specificity z obiektów stworzonych przy wykorzystaniu biblioteki pROC , tak aby wykreślić wiele krzywych ROC na jednym wykresie ggplot2.
library(pROC)
#stworzenie obiektóe ROC
roc_train <- pROC::roc(train$PM10_ex, pred_prob_train)
roc_test <- pROC::roc(test$PM10_ex, pred_prob_test)
auc(roc_train)Area under the curve: 0.9623auc(roc_test)Area under the curve: 0.9215# "wyciągamy" wartości sensitivity i specificity z obiektów
# roc_train i roc_test , żeby wykreślić je w ggplot
gg_roc_train <- data.frame(sens = roc_train$sensitivities,
spec = roc_train$specificities)
gg_roc_test <- data.frame(sens = roc_test$sensitivities,
spec = roc_test$specificities)
ggplot(gg_roc_train, aes(x = spec, y = sens))+
geom_path()+
geom_path(data = gg_roc_test, color = "red")+
scale_x_reverse()+
labs(
x = "Specificity (1-False Alarm Rate)",
y = "Sensitivity"
)+
theme_bw()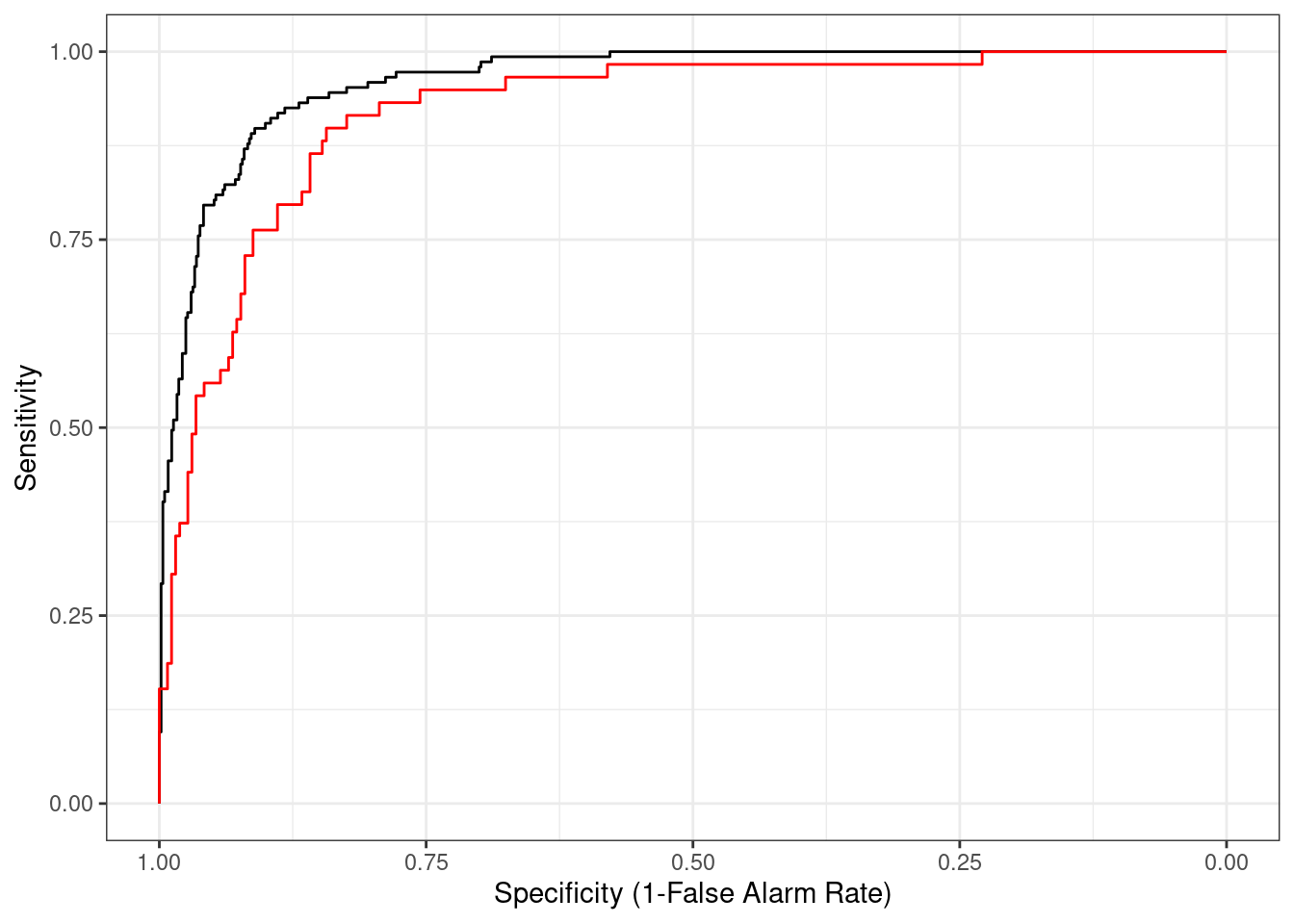
Wygląda na to, że nasz model całkiem nieźle sprawdza się na danych testowych (czerwona krzywa ROC). Widoczny jest nieznaczny spadek jakości, no ale tego należało się spodziewać. Miara AUC jest tylko nieco niższa (0,92 względem 0,96) niż dla modelu ocenianego na podstawie danych wykorzystanych w kalibracji.
7.5.1 Nierównowaga w danych
Nasze zmienne cechują się nierównowagą, czyli znaczą różnicą między liczebnością przypadków przekroczenia progu 30\(\mu \text{g/m}^3\), a pozostałymi. Może to powodować problemy w kontekście aplikacyjności modelu, ponieważ nie będzie on miał wystarczającej bazy przypadków z przekroczeniem aby “nauczyć się” je rozpoznawać. Trzeba to zweryfikować.
Najpierw zerknijmy na proporcje.
table(train$PM10_ex)
0 1
604 147 prop.table(table(train$PM10_ex))
0 1
0.804261 0.195739 W ciągu kalibrującym zaledwie 19,5% danych to przypadki przekroczenia normy PM10.
Posłużymy się procedurą overscaling’u (przy czym zastosujemy metodę over), aby zrównoważyć tą proporcję
library(ROSE)
train_both <- ovun.sample(PM10_ex ~ .,
data = train,
method = "over",
N = 1200)$datazerknijmy teraz na proporcję
table(train_both$PM10_ex)
0 1
604 596 prop.table(table(train_both$PM10_ex))
0 1
0.5033333 0.4966667 I ponownie skalibrujmy model (model_train_both) ze zrównoważonymi liczebnościami. Zobaczymy czy poprawi to jego jakość podczas ewaluacji na danych testowych.
model_train_both <- glm(PM10_ex ~ .,
data = train_both,
family = binomial)
summary(model_train)
Call:
glm(formula = PM10_ex ~ ., family = "binomial", data = train)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -18.29262 14.53677 -1.258 0.20826
TMIN 0.25993 0.23963 1.085 0.27805
TMAX 0.56241 0.24786 2.269 0.02327 *
T2M -1.09003 0.47943 -2.274 0.02299 *
TP -0.08462 0.08944 -0.946 0.34409
MSL 0.01755 0.01433 1.224 0.22081
D2M 0.19665 0.12876 1.527 0.12668
U10 -0.19100 0.06261 -3.051 0.00228 **
V10 0.99493 0.13926 7.144 9.05e-13 ***
VEL10 -1.30201 0.18400 -7.076 1.48e-12 ***
PM10_lag1 0.10169 0.01465 6.940 3.91e-12 ***
PM10_lag2 0.01428 0.01170 1.221 0.22223
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 742.65 on 750 degrees of freedom
Residual deviance: 292.32 on 739 degrees of freedom
AIC: 316.32
Number of Fisher Scoring iterations: 8Nie będziemy liczyć ponownie wszystkich statystyk. Zerknijmy, czy poprawiła się nasza ROC.
Musimy obliczyć nowy punkt odcięcia dla tego modelu.
library(pROC)
pred_prob_train_both <- predict(model_train_both, newdata = train, type = "response")
roc_obj_both <- roc(train$PM10_ex, pred_prob_train_both)
opt_cut_both <- coords(roc_obj_both,
x = "best",
best.method = "youden",
ret = "threshold")
opt_cut_both threshold
1 0.5286766#opt_cut_both[[1]]Widać, że wartość ta znacznie różni się od progu przed równoważeniem danych.
Predykcja prawdopodobieństwa na ciągu testowym dla zrównoważonych danych.
#
pred_prob_test_both <- predict(model_train_both,
newdata = test,
type = "response")library(pROC)
roc_train <- pROC::roc(train$PM10_ex, pred_prob_train)
roc_test <- pROC::roc(test$PM10_ex, pred_prob_test)
roc_test_both <- pROC::roc(test$PM10_ex, pred_prob_test_both)
auc(roc_train)Area under the curve: 0.9623auc(roc_test)Area under the curve: 0.9215auc(roc_test_both)Area under the curve: 0.9213gg_roc_train <- data.frame(sens = roc_train$sensitivities,
spec = roc_train$specificities)
gg_roc_test <- data.frame(sens = roc_test$sensitivities,
spec = roc_test$specificities)
gg_roc_test_both <- data.frame(sens = roc_test_both$sensitivities,
spec = roc_test_both$specificities)
ggplot(gg_roc_train, aes(x = spec, y = sens))+
geom_path()+
geom_path(data = gg_roc_test, color = "red")+
geom_path(data = gg_roc_test_both, color = "darkgreen")+
labs(
x = "Specificity (1-False Alarm Rate)",
y = "Sensitivity"
)+
scale_x_reverse()+
theme_bw()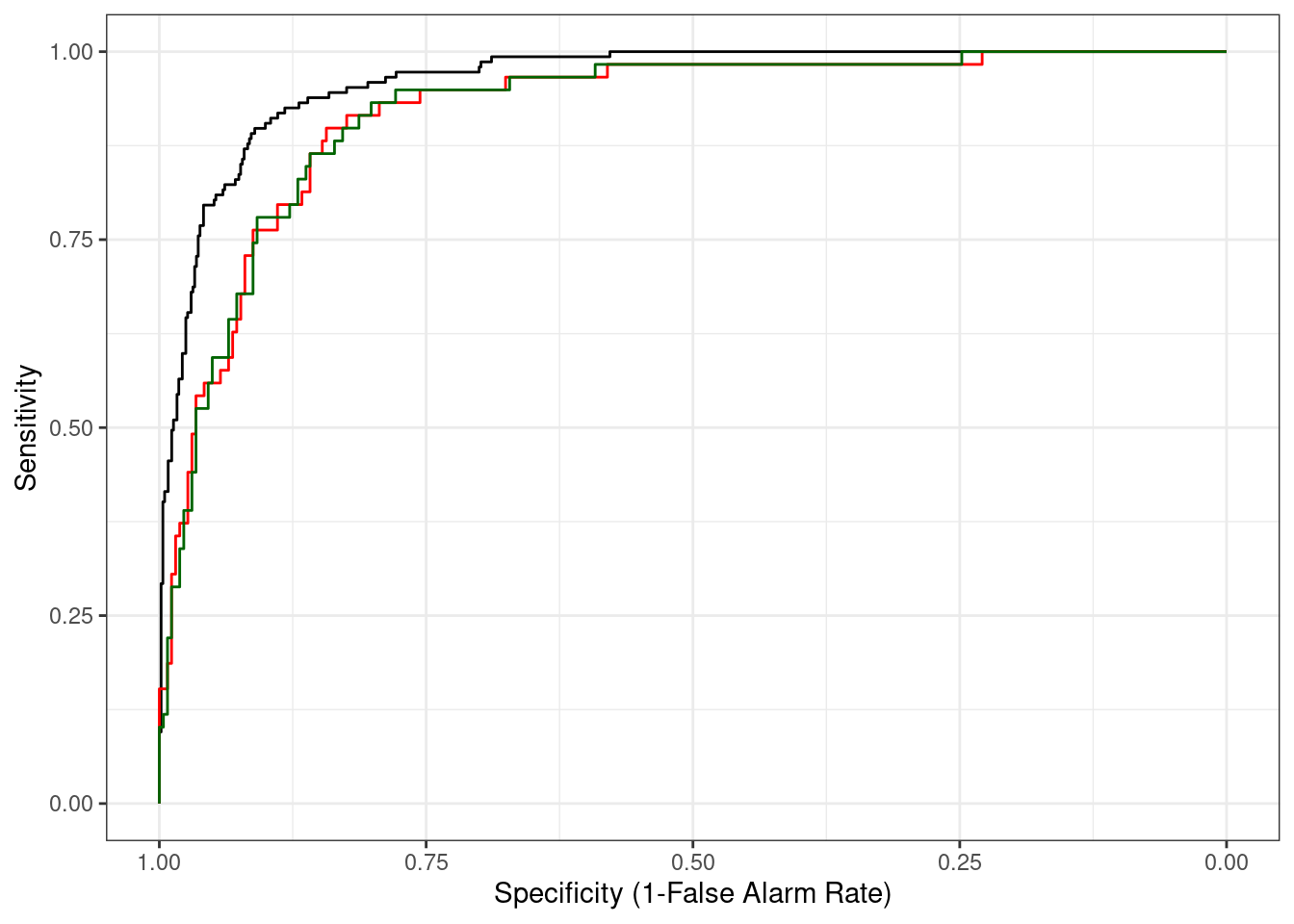
Zielona linia to ROC po oversamplingu. W zasadzie można zaryzykować stwierdzenie, że nie zaznacza się wzrost jakości modelu względem opartego jedynie na danych oryginalnych z niezrównoważonymi liczebnościami klas PM10_ex. Niemniej jednak obliczmy confusion matrix dla tego wariantu.
# Predykcja prawdopodobieństw na podstawie modelu ze zrównoważoną
# liczbą przypadków ekstremalnych i wyznaczenie wystapienia przypadków
# ekstremalnych na podstawie optymalnego punktu oscięcia.
pred_prob_test_both <- predict(model_train_both, newdata = test, type = "response")
pred_class_test_both <- ifelse(pred_prob_test_both > opt_cut_both[[1]], 1, 0)
confusionMatrix(data = as.factor(pred_class_test_both),
reference = as.factor(test$PM10_ex),
positive = "1")Confusion Matrix and Statistics
Reference
Prediction 0 1
0 229 12
1 33 47
Accuracy : 0.8598
95% CI : (0.817, 0.8959)
No Information Rate : 0.8162
P-Value [Acc > NIR] : 0.023095
Kappa : 0.5894
Mcnemar's Test P-Value : 0.002869
Sensitivity : 0.7966
Specificity : 0.8740
Pos Pred Value : 0.5875
Neg Pred Value : 0.9502
Prevalence : 0.1838
Detection Rate : 0.1464
Detection Prevalence : 0.2492
Balanced Accuracy : 0.8353
'Positive' Class : 1
Wynik potwierdza ocenę wizualną ROC i nie mamy tutaj do czynienia z wyraźną poprawą jakości modelu na skutek zrównoważenia klas.
7.6 Szybkie statystyki modelu
Jeżeli zależy nam na obliczeniu tylko wybranych charakterystyk np. w celu szybkiego przygotowania zestawienia dla wielu modeli, polecam bibliotekę verification. Ma ona, co prawda, swoje lata i czasami potrafi sprawić nieco problemów (np, jeżeli pojawiają braki danych w seriach), jednak zazwyczaj sprawuje się poprawnie.
library(verification)Obliczmy dla modelu model_train_both następujące metryki: Accuracy (PC - percent correct), CSI (Threat Score), BIAS, POD i HSS. Stworzymy następnie ramkę danych metrics z wynikami.
pc <- verify(obs=test$PM10_ex,
pred = pred_class_test_both,
frcst.type = "binary",
obs.type = "binary")$PC
csi <- verify(obs=test$PM10_ex,
pred = pred_class_test_both,
frcst.type = "binary",
obs.type = "binary")$TS
bias <- verify(obs=test$PM10_ex,
pred = pred_class_test_both,
frcst.type = "binary",
obs.type = "binary")$BIAS
pod <- verify(obs=test$PM10_ex,
pred = pred_class_test_both,
frcst.type = "binary",
obs.type = "binary")$POD
hss <- verify(obs=test$PM10_ex,
pred = pred_class_test_both,
frcst.type = "binary",
obs.type = "binary")$HSS
metrics = round(data.frame(pc = pc, csi = csi, bias = bias, pod = pod, hss = hss), digits = 2)
metrics pc csi bias pod hss
1 0.86 0.51 1.36 0.8 0.59Jak widać zastosowanie regresji logistycznej (kalibracja modelu) nie jest trudne. Bardziej złożonym zagadnieniem jest ocena i porównanie jakości modeli. Tym bardziej, że istnieje legion metryk, które często nazywane są w różny sposób w literaturze, co dodatkowo utrudnia zorientowanie się w ich gąszczu. Dobór metryk jakości zawsze powinien być podyktowany potencjalnym zastosowaniem kalibrowanego modelu oraz charakterem zmiennej wyjaśnianej.
Po więcej usystematyzowanych informacji zapraszamy na kursy DataCraft LAB.
Specificity = 1 - False Alarm Rate↩︎