load("data/final_daily.rda")6 Kalibracja, testowanie, nierównowaga, skośność
Problem do rozwiązania: poprawny podział danych na cześć kalibracyjną i testującą, nierównowaga w danych, korekta rozkładów zmiennych.
Słowa kluczowe: próba kalibrująca i testująca, nierównowaga klas, SMOTE, preprocesing danych wejściowych
6.1 Dane
Dane wykorzystane w niniejszym wpisie zostały stworzone bazując na dwóch zbiorach: pierwszy to Reanaliza ERA5 (C3S 2018), drugi natomiast to publicznie dostępny bank danych GIOŚ, obejmujący dane dotyczące zmienności zanieczyszczeń powietrza na stacjach pomiarowych w Polsce.
Wybrano stację położoną w Gdyni w dzielnicy Pogórze na ul. Porębskiego. Jej kod międzynarodowy to PL0048A a koordynaty \(\lambda\)=18,493331, \(\phi\)=54,560836.
Dane z Reanalizy ERA5 pochodzą z punktu gridowego najbliższego koordynatom stacji na ulicy Porębskiego.
Dane obejmowały wartości z rozdzielczością czasową 1h i zostały następnie przetworzone do wartości średnich dobowych lub tam gdzie miało to zastosowanie (np. w przypadku opadów) do sum dobowych. Dobowe średnie/sumy zmiennych meteorologicznych oraz stężenia PM10 były obliczane, jeżeli liczba pomiarów w dobie przekraczała 75% przypadków, czyli 18. Jeżeli ten warunek nie był spełniony wprowadzano do bazy oznaczenie braku danych NA.
Dane można pobrać tutaj.
6.2 Motywacja
Przygotowanie danych wejściowych do modeli jest kluczowym elementem analizy.
Dane środowiskowe ekstremalnie rzadko nadają się do zastosowania out-of-the-box. Zazwyczaj w procedurze niezbędne są poniższe kroki:
import danych surowych,
czyszczenie danych, usunięcie zbędnych zmiennych, kodowanie kategorii,
podział na ciąg kalibrujący i testujący,
skalowanie / transformacja (center, scale, Yeo-Johnson),
oversampling/downsampling (pakiety ROSE i SMOTE) - likwidacja nierównowagi między klasami,
trening modelu.
6.3 Import danych, usunięcie zbędnych zmiennych i kodowanie kategorii
Załadujmy dane
Zerknijmy na strukturę.
str(final_daily)Classes 'tbl_df', 'tbl' and 'data.frame': 4383 obs. of 14 variables:
$ DATE : Date, format: "2013-01-01" "2013-01-02" ...
$ YEAR : num 2013 2013 2013 2013 2013 ...
$ MONTH: num 1 1 1 1 1 1 1 1 1 1 ...
$ DAY : int 1 2 3 4 5 6 7 8 9 10 ...
$ TMIN : num 3.27 3.18 2.3 3.4 1.07 ...
$ TMAX : num 5.03 4.38 7.01 5.6 3.73 ...
$ T2M : num 4.15 3.69 4.87 4.83 2.72 ...
$ PM10 : num NA NA NA NA NA NA NA NA NA NA ...
$ TP : num 1.2465 0.7515 5.372 0.0987 0.2246 ...
$ MSL : num 1003 1012 1012 1015 1022 ...
$ D2M : num 1.7569 2.341 3.4214 2.7618 0.0643 ...
$ U10 : num 3.85 5.28 8.21 6.5 1.39 ...
$ V10 : num 5.652 1.941 0.363 -3.42 -6.051 ...
$ VEL10: num 6.88 5.74 8.95 7.44 6.37 ...Dane obejmują okres czasu 2013-2024, przy czym PM10 dostępne są od 1-01-2015. Zmienne meteorologiczne to:
TMAX - maksymalna dobowa temperatura powietrza [°C]
TMIN - minimalna dobowa temperatura powietrza [°C]
T2M - średnia dobowa temperatura powietrza [°C]
TP - dobowa suma opadu [mm]
MSL - średnie dobowe ciśnienie na poziomie morza [hPa]
D2M - średnia dobowa temperatura punktu rosy [°C]
U10 - średnia dobowa składowa równoleżnikowa wektora wiatru [m/s]
V10 - średnia dobowa składowa południkowa wektora wiatru [m/s]
VEL10 - średnia dobowa prędkość wiatru [m/s]
PM10 to średnie dobowe stężenie pyłu zawieszonego PM10 [\(\mu \text{g/m}^3\)].
Krótkie podsumowanie naszych danych.
summary(final_daily) DATE YEAR MONTH DAY
Min. :2013-01-01 Min. :2013 Min. : 1.000 Min. : 1.00
1st Qu.:2016-01-01 1st Qu.:2016 1st Qu.: 4.000 1st Qu.: 8.00
Median :2019-01-01 Median :2019 Median : 7.000 Median :16.00
Mean :2019-01-01 Mean :2019 Mean : 6.523 Mean :15.73
3rd Qu.:2021-12-31 3rd Qu.:2022 3rd Qu.:10.000 3rd Qu.:23.00
Max. :2024-12-31 Max. :2024 Max. :12.000 Max. :31.00
TMIN TMAX T2M PM10
Min. :-14.263 Min. :-11.070 Min. :-12.484 Min. : 3.227
1st Qu.: 1.392 1st Qu.: 5.213 1st Qu.: 3.477 1st Qu.: 9.729
Median : 5.972 Median : 11.372 Median : 8.741 Median : 14.260
Mean : 6.365 Mean : 11.573 Mean : 9.087 Mean : 17.624
3rd Qu.: 12.017 3rd Qu.: 18.169 3rd Qu.: 15.385 3rd Qu.: 22.095
Max. : 21.476 Max. : 30.427 Max. : 25.586 Max. :112.271
NA's :1162
TP MSL D2M U10
Min. : 0.00000 Min. : 972.2 Min. :-14.4959 Min. :-9.929
1st Qu.: 0.06437 1st Qu.:1009.3 1st Qu.: 0.9262 1st Qu.:-1.351
Median : 0.61083 Median :1015.1 Median : 5.5154 Median : 1.440
Mean : 2.12145 Mean :1014.8 Mean : 5.8156 Mean : 1.393
3rd Qu.: 2.70629 3rd Qu.:1020.8 3rd Qu.: 11.3634 3rd Qu.: 4.012
Max. :54.22163 Max. :1046.4 Max. : 21.1175 Max. :12.875
V10 VEL10
Min. :-11.4394 Min. : 1.023
1st Qu.: -1.3818 1st Qu.: 3.527
Median : 0.6145 Median : 4.721
Mean : 0.6121 Mean : 4.956
3rd Qu.: 2.7275 3rd Qu.: 6.122
Max. : 10.0851 Max. :13.967
Zaczniemy od utworzenia dodatkowej zmiennej binarnej (1, 0), która będzie przyjmować wartość 1, kiedy dobowe stężenie PM10 przekroczy 401 \(\mu \text{g/m}^3\).
library(dplyr)
final_daily <- final_daily %>%
mutate(PM10_ex = if_else(PM10 > 40, 1, 0))A następnie usuniemy wiersze posiadające braki danych - pojawiały się tylko w przypadku zmiennej PM10, więc stosujemy dplyr i funkcję !is.na().
Finalnie, usuwamy naszą oryginalną ramkę
dane <- final_daily %>%
filter(!is.na(PM10))
rm(final_daily)6.4 Podział na ciąg kalibrujący i testujący
Dlaczego warto dzielić dane na zbiór uczący i testujący?
W procesie budowy modeli predykcyjnych (szczególne w przypadku zastosowania wyrafinowanych współczesnych metod z zakresu uczenia maszynowego) kluczowe znaczenie ma rzetelna ocena ich skuteczności. Aby to osiągnąć, dane należy podzielić na zbiór uczący, na którym model się “uczy”, oraz zbiór testujący, który służy do sprawdzenia, jak dobrze model radzi sobie z nowymi, nieznanymi danymi. Taki podział pozwala uniknąć przeuczenia (overfitting’u) i dostarcza wiarygodnych informacji o zdolności generalizacji modelu.
Dzięki temu jesteśmy w stanie nie tylko opisać dane historyczne (zidentyfikować i ilościowo opisać powiązania między predyktorami, a predyktantą), lecz także realnie prognozować przyszłe zdarzenia i podejmować decyzje w oparciu o dane — np. klasyfikować klientów, przewidywać awarie, diagnozować choroby, czy wykrywać oszustwa.
Bez poprawnie przeprowadzonego podziału model może sprawiać wrażenie dokładnego, ale zawodzić w praktyce — tam, gdzie najbardziej liczy się jego skuteczność.
Załóżmy, że chcemy nasze dane podzielić na dwie ramki:
train - która posłuży nam następnie do kalibracji modelu
test - tą wykorzystamy do jego oceny
Żeby wybrać losowo pewien odsetek rekordów z danych można wykorzystać funkcję sample(), przy czym niestety jest ona ślepa na proporcje między klasami (jeżeli analizujemy zmienną kategoryczną - dwie lub więcej wykluczające się klasy), oraz kształt rozkładu (w przypadku zmiennej w skali interwałowej lub ilorazowej).
Tego typu podejście może spowodować, że w modelu który stworzymy klasy nie będą reprezentowane zgodnie z ich globalnymi proporcjami, co spowoduje upośledzenie jego jakości.
W przypadku zmiennej ciągłej kształt rozkładu będzie odmienny w ciągu testującym i kalibrującym, co również nie pozostanie bez wpływu na jakość modeli.
Zapobiegniemy powyższym problemom, posługując się funkcją createDataPartition() z paczki caret, która zapewni odpowiednie odzwierciedlenie charakterystyk zmiennej zależnej w obu ciągach: kalibrującym i testującym.
Aby stworzyć ramki danych train i test stosujemy funkcję createDataPartition().
Zakładamy, że ramka kalibrująca będzie zawierać 70% danych, natomiast testująca 30% (stąd wartość argumentu p wynosząca 0.7).
Wcześniej wybierzemy z naszej ramki danych tylko miesiące zimowe (12, 1, 2)
# wybór miesięcy zimowych
dane <- dane %>%
filter(MONTH %in% c(12, 1, 2))
# załadowanie biblioteki caret i stworzenie ciągów: kalibracyjnego
# i testującego
library(caret)
set.seed(123)
# stwórzymy index
index <- createDataPartition(dane$PM10_ex, p = 0.7, list = FALSE)
train <- dane[index, ]
test <- dane[-index, ]Sprawdźmy jak wyglądają proporcje klas zmiennych PM10_ex w obu ramkach:
table(train$PM10_ex)
0 1
502 57 i w procentach:
prop.table(table(train$PM10_ex))*100
0 1
89.80322 10.19678 I to samo dla ramki test:
table(test$PM10_ex)
0 1
215 24 prop.table(table(test$PM10_ex))*100
0 1
89.95816 10.04184 Jak widać proporcje są niezwykle zbliżone, co pozwala nam mieć nadzieję, że nasz model będzie się “uczył” na danych odzwierciedlających rzeczywistość.
Funkcja ta może również zostać zastosowana do zmiennej ciągłej (dla modeli z ciągłą zmienną wyjściową). W naszym przykładzie posłużymy się zmienną PM10.
Jednym z argumentów funkcji createDataPartition() jest groups, który wskazuje na ile przedziałów w tle jest dzielona nasza zmienna. Następnie, ich lizczebności są równoważone między ciągiem kalibrującym, a testującym. Domyślnie wartość ta wynosi 5, przy czym im jest wyższa, tym histogramy zmiennej w ciągu kalibracyjnym i testującym będą bardziej zbliżone.
Najpierw przykład na ustawieniach domyślnych (nie wpisujemy wartości argumentu).
library(caret)
set.seed(123)
# stwórzymy index
index <- createDataPartition(dane$PM10, p = 0.7, list = FALSE)
train_g5 <- dane[index, ]
test_g5 <- dane[-index, ]i zerknijmy na wykresy.
library(ggplot2)
ggplot(train_g5, aes(x = PM10))+
geom_density(fill = "red", alpha = 0.5)+
geom_density(data = test_g5, fill = "navy", alpha = 0.5)+
theme_bw()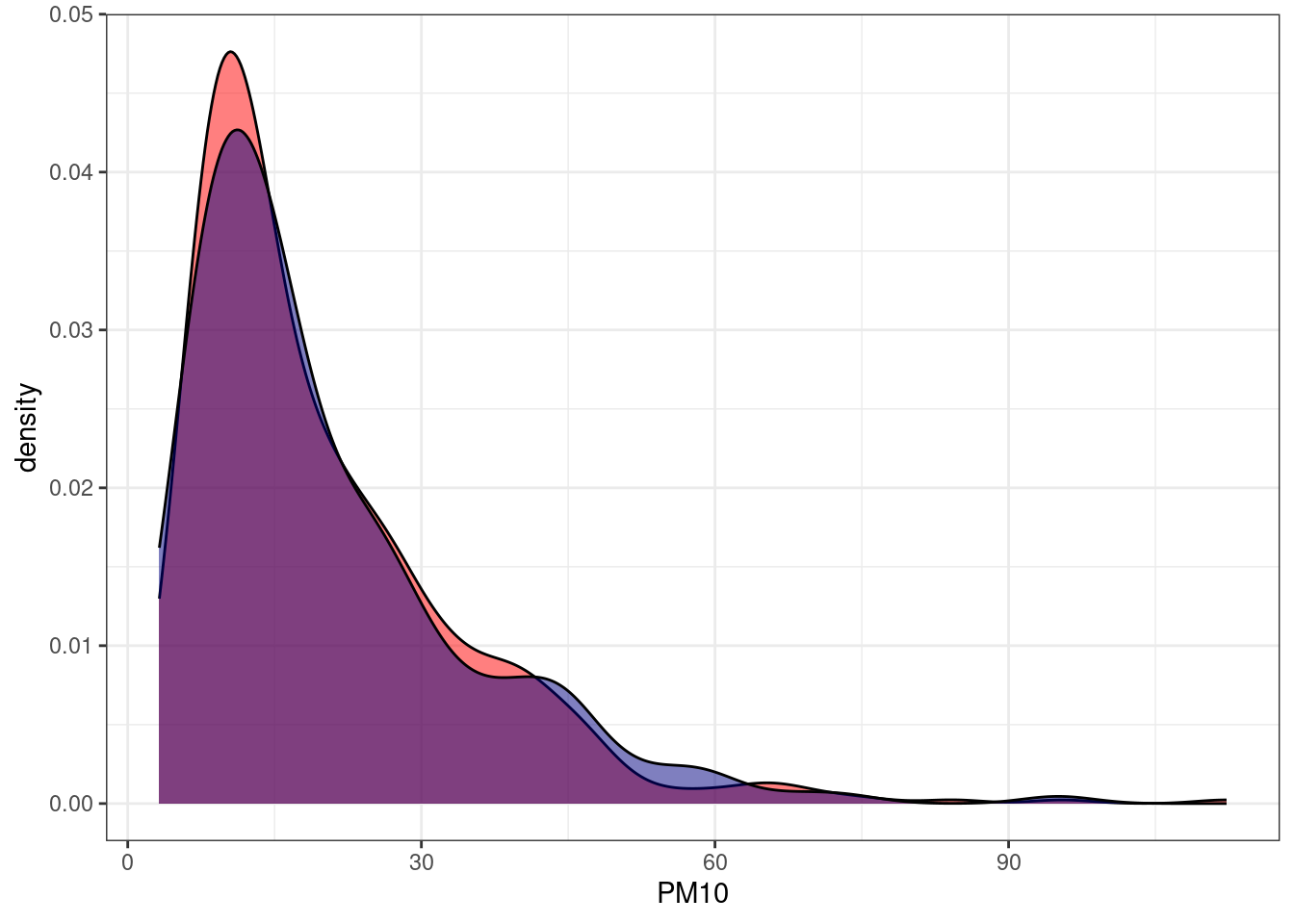
Rozkłady niemalże się pokrywają.
Teraz to samo, ale z większą liczbą klas (30):
library(caret)
set.seed(123)
# stwórzymy index
index <- createDataPartition(dane$PM10,
p = 0.7,
list = FALSE,
groups = 30)
train_g30 <- dane[index, ]
test_g30 <- dane[-index, ]library(ggplot2)
ggplot(train_g30, aes(x = PM10))+
geom_density(fill = "red", alpha = 0.5)+
geom_density(data = test_g30, fill = "navy", alpha = 0.5)+
theme_bw()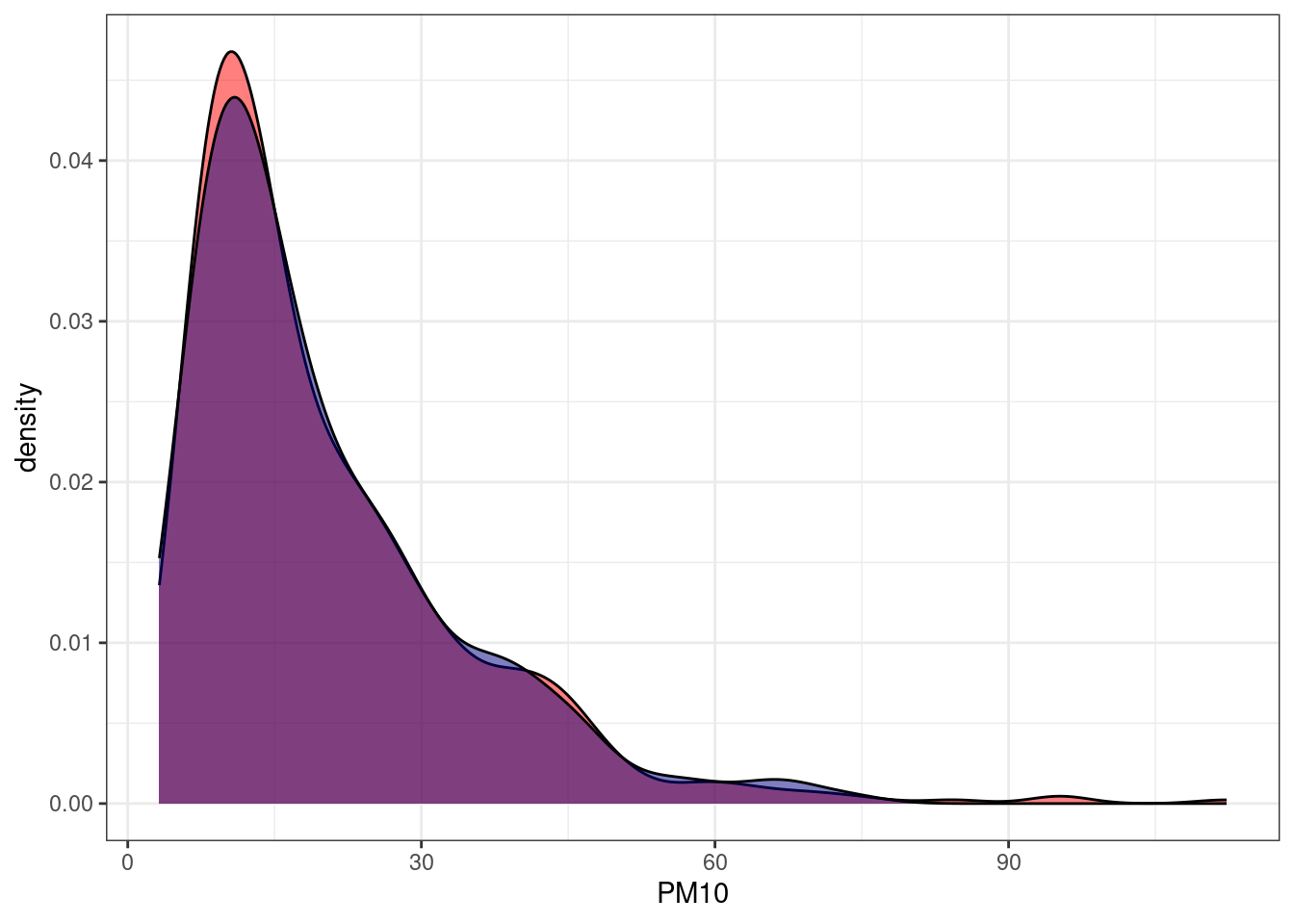
Dopasowanie nieco się poprawiło.
Powyższe działania są absolutnie niezbędne w procedurach kalibracji i ewaluacji modeli. Bez wydzielenia ciągu testującego nie mamy możliwości weryfikacji działania modelu na nowych zmiennych.
6.5 Transformacja danych
Zmienne środowiskowe rzadko kiedy mają rozkład normalny oraz opisywane są w tej samej skali. Może to powodować problemy podczas samej kalibracji modeli jak również wpływać negatywnie na ich jakość. Niezbędna jest wówczas ich transformacja i/lub skalowanie.
Zerknijmy jak to wygląda w przypadku naszych danych.
Można to wykonać korzystając z pakiety GGally i funkcji ggpairs().
library(GGally)
ggpairs(select(dane, -DATE:-DAY),
lower = list(continuous = wrap("points", size = 0.5, alpha = 0.4)))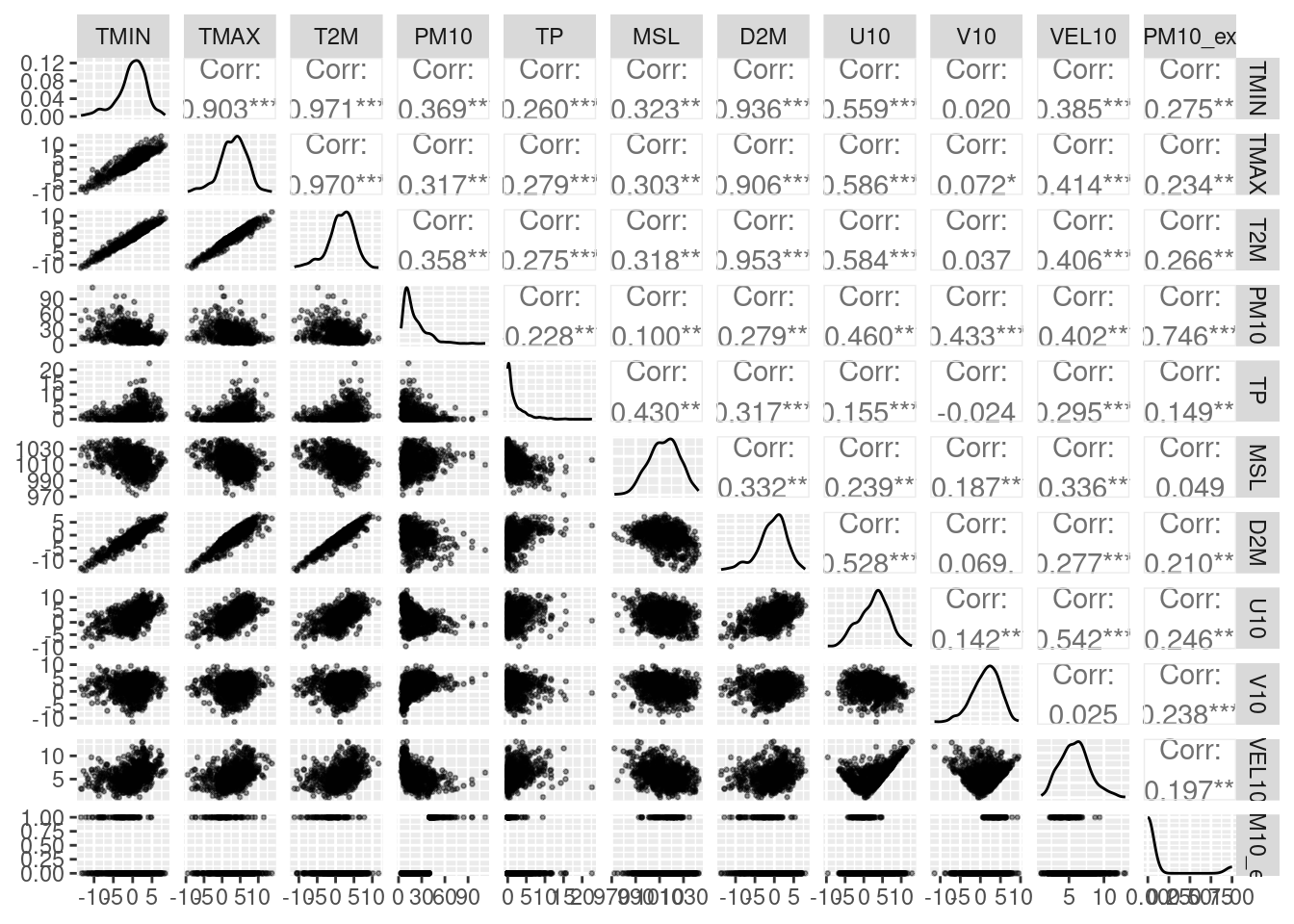
Kilka zmiennych ma ewidentnie skośne rozkłady, w tym PM10, ale ponieważ zajmujemy się zagadnieniami klasyfikacyjnymi, więc chwilowo możemy o niej zapomnieć (powinna ona zostać nawet usunięta przed kalibracją modelu).
Pozostałe problematyczne (o znacznej skośności) zmienne to: TP, D2M, V10 oraz VEL10.
W celu transformacji i standaryzacji zmiennych posłużymy się funkcją preProcess() z biblioteki caret.
Zastosujemy zarówno skalowanie (standaryzację) jak i jedną z częściej stosowanych transformację Yeo-Johnson’a.
library(caret)
# 1. Tworzymy obiekt scale_trans na podstawie ramki train, ktory
# zapisze informacje niezbędne do powtórzenia procedury na zbiorze
# testującym oraz przyszłych danych. Usuwamy zmienną PM10_ex. Jest
# ona zmienną binarną i nie ma potrzeby jej przekształcania.
scale_trans <- preProcess(select(train, -DATE:-DAY, -PM10_ex), method = c("YeoJohnson", "center", "scale"))
# 2. Zastosowanie na zbiorze uczącym i testowym
train_scaled <- predict(scale_trans, select(train, -DATE:-DAY, -PM10_ex))
test_scaled <- predict(scale_trans, select(test, -DATE:-DAY, -PM10_ex))
# 3. Do pretransformowanych danych dodajemy zmienną
# zależną PM10_ex.
train_scaled$PM10_ex <- train$PM10_ex
test_scaled$PM10_ex <- test$PM10_exI ponownie zerknijmy jak wyglądają rozkłady po transformacji:
library(GGally)
ggpairs(train_scaled,
lower = list(continuous = wrap("points", size = 0.5, alpha = 0.4)))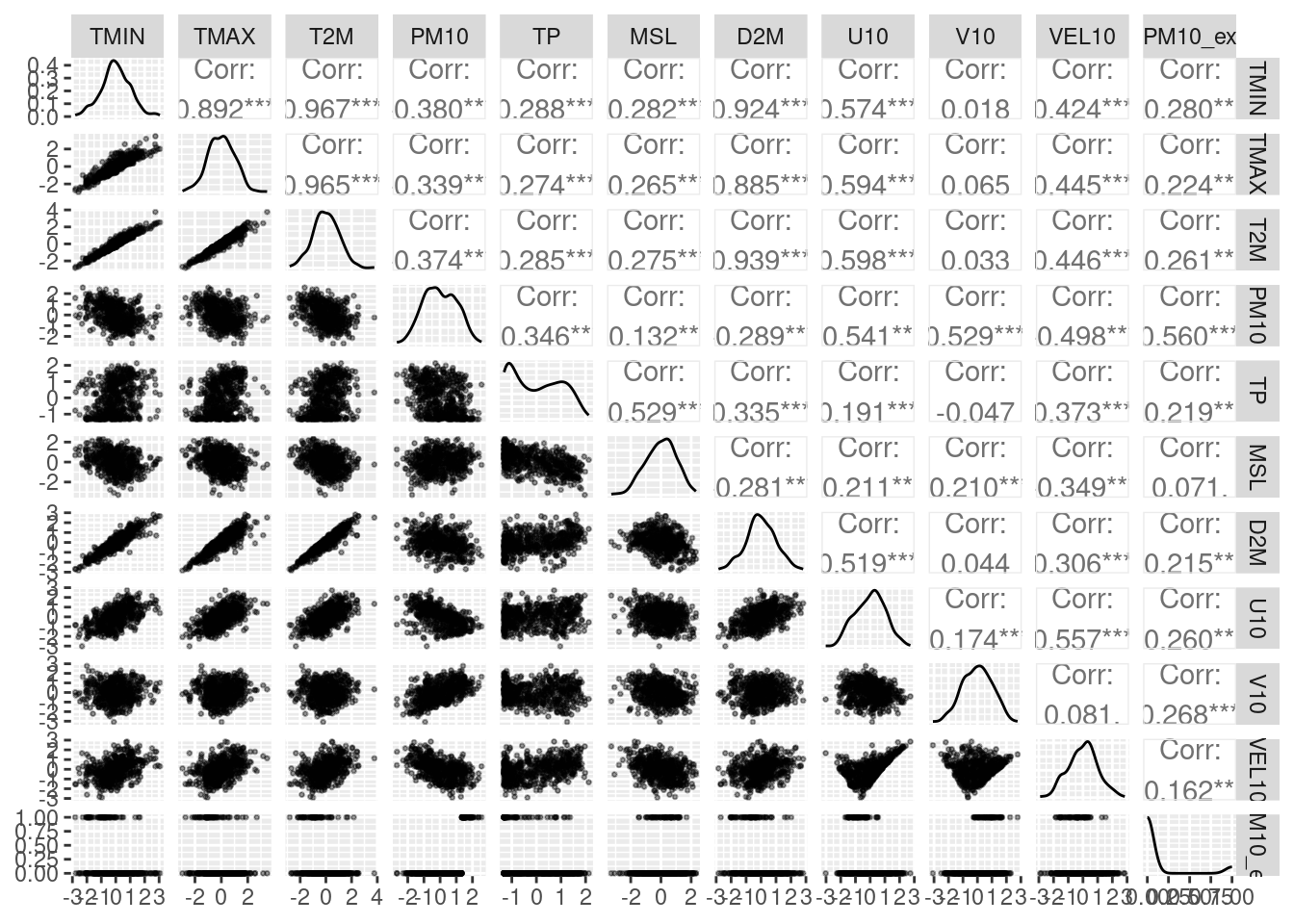
ggpairs(test_scaled,
lower = list(continuous = wrap("points", size = 0.5, alpha = 0.4)))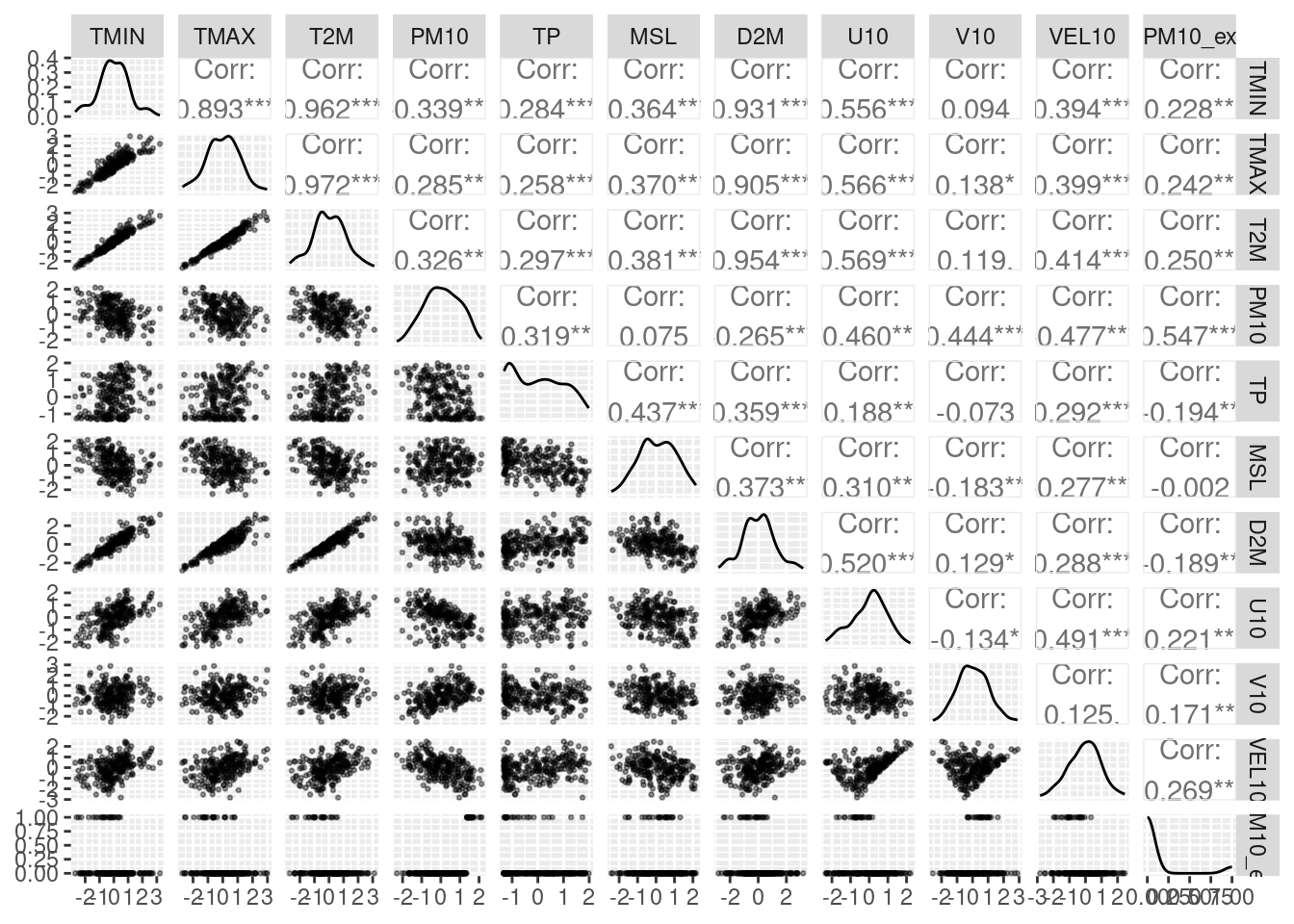
Nastąpiła wyraźna poprawa w kontekście rozkładów a wszystkie zmienne mają zunifikowane skale.
Jeżeli zaistnieje taka konieczność, np. w celach informacyjnych, warto również przywrócić zmienne dotyczące czasu, tak aby poszczególne przypadki były łatwo identyfikowalne.
6.6 Nierównowaga
Nierównowaga klas — cichy wróg modeli predykcyjnych
W wielu rzeczywistych zastosowaniach dane nie są równomiernie rozłożone między kategoriami. Przykład? Wykrywanie oszustw, diagnozowanie rzadkich chorób, analiza ekstremów meteorologicznych, czy prognozowanie awarii — przypadki pozytywne stanowią zaledwie kilka procent (czasami mniej) obserwacji. To właśnie nierównowaga klas (ang. imbalanced data).
Dlaczego to problem? Modele uczone na takich danych mają tendencję do ignorowania klasy mniejszościowej, bo optymalizacja błędu “nagradza” za trafne przewidywanie dominującej grupy. W efekcie możemy otrzymać wysoką dokładność, a jednocześnie kompletny brak użyteczności – np. model, który nigdy nie wykrywa przypadków oszustwa, mimo że twierdzi, że jest “dokładny w 98%”.
Dlatego w pracy z danymi niezbalansowanymi nie wystarczy tylko trenować model – trzeba umiejętnie dobrać metryki (np. F1-score, recall, AUC) i stosować metody takie jak SMOTE, ważenie klas czy resampling. Tylko wtedy model może znaleźć zastosowanie w rzeczywistości — tam, gdzie rzadkie przypadki są często najważniejsze.
Co ze zmiennymi ciągłymi?
Choć problem nierównowagi najczęściej kojarzymy z klasyfikacją (np. z przewagą jednej klasy nad drugą), to w modelach regresyjnych również może dojść do zniekształcenia wyników – jeśli rozkład wartości zmiennej ciągłej jest silnie skośny lub dominują przypadki o „typowych” wartościach.
W takich sytuacjach:
model uczy się przewidywać wartości „średnie”, a ignoruje skrajności (np. wysokie koszty leczenia, duże zużycie energii),
dokładność pozorna rośnie, ale trafność w przypadkach krytycznych – spada.
Jak sobie z tym radzić?
transformacje zmiennej zależnej (np. logarytmiczna, standaryzacja, Yeo-Johnson),
stratyfikacja w podziale danych na podstawie przedziałów wartości,
ważenie obserwacji w modelu – większy wpływ dla rzadkich wartości.
Równowaga w danych to nie tylko kwestia klas – to fundament modeli, które chcą zrozumieć także przypadki nietypowe.
Poniżej kilka z możliwych do zastosowania metod. Z premedytacją pomijam metodę downscale, ponieważ prowadzi ona do usuwania znacznej ilości danych w celu zrównoważenia liczebności klas. Rzadko kiedy jest to uzasadnione działanie.
Rzecz najważniejsza!
Procedurom równoważenia klas poddawana jest TYLKO ramka kalibrująca (train), bo to na niej nasz model będzie się uczył. Weryfikować jego jakość będziemy z wykorzystaniem ramki test, która sprawdzi jak model zachowuje się w rzeczywistych warunkach.
Pracujemy na wcześniej wygenerowanej ramce danych train z dodatkową zmienną PM10_ex
Sprawdzamy rozkład klas w PM10_ex
table(train_scaled$PM10_ex)
0 1
502 57 prop.table(table(train_scaled$PM10_ex))
0 1
0.8980322 0.1019678 6.6.1 Oversampling (pakiet ROSE)
Procedurą oversamplingu wykonujemy z wykorzystaniem funkcji ovun.sample z pakietu ROSE.
library(ROSE)
train_scaled_over <- ovun.sample(PM10_ex ~ .,
data = train_scaled,
method = "over",
N = 1004)$dataMożna przyjąć następującą zgrubną zasadę przy doborze argumentu N (finalny rozmiar próby po oversamplingu) - wiedząc, że liczba przypadków klasy “0” wynosi 502 i zakładając, że nie chcemy tracić informacji z tej klasy, a jednocześnie chcemy, aby klasy się równoważyły po prostu podwajamy tą wartość.
W przypadku oversamplingu klasa mniejszościowa jest wielokrotnie losowana (ze zwracaniem) z oryginalnego zbioru. Przypadki z klasą większościowa są pozostawiane bez zmian. Losowanie trwa do momentu, aż nasza nowa ramka będzie miała liczbę rekordów wskazaną w argumencie N.
Sprawdźmy jak teraz wyglądają klasy:
table(train_scaled_over$PM10_ex)
0 1
502 502 prop.table(table(train_scaled_over$PM10_ex))
0 1
0.5 0.5 Mała dygresja
Inna opcja to zastosowanie metody “both” zamiast “over” i wówczas możemy wpisać nawet wartość 2347, a algorytm odpowiednio wylosuje przypadki z odpowiednich klas zgodnie z proporcją wskazaną w argumencie p. Działa to w dwie strony, czyli możemy również ograniczyć rozmiar naszego ciągu uczącego.
Przykładowo:
library(ROSE)
#dla N = 2347 i proporcji 0.5
train_scaled_2347 <- ovun.sample(PM10_ex ~ .,
data = train_scaled,
method = "both",
p = 0.5,
N = 2347)$data
# liczebności
table(train_scaled_2347$PM10_ex)
0 1
1175 1172 # proporcje
prop.table(table(train_scaled_2347$PM10_ex))
0 1
0.5006391 0.4993609 # dla N = 200
#dla N = 200 i proporcji 0.5
train_scaled_200 <- ovun.sample(PM10_ex ~ .,
data = train_scaled,
method = "both",
p = 0.5,
N = 200)$data
#liczebności
table(train_scaled_200$PM10_ex)
0 1
117 83 # proporcje
prop.table(table(train_scaled_200$PM10_ex))
0 1
0.585 0.415 Jak widać, w przypadku ograniczania liczebności próby możliwy jest efekt kiedy wymuszenie równowagi klas nie zadziała idealnie.
6.6.2 SMOTE - Synthetic Minority Over-sampling Technique
SMOTE to popularna metoda radzenia sobie z nierównowagą klas w problemach klasyfikacyjnych. Działa inaczej niż zwykły oversampling, ponieważ zamiast kopiować (wielokrotnie losować) obserwacje z klasy mniejszościowej, tworzy nowe syntetyczne przypadki na podstawie już istniejących.
Jak działa?
Dla każdej obserwacji z klasy mniejszościowej wybieranych jest kilku najbliższych sąsiadów (np. 5).
Tworzone są nowe, syntetyczne punkty wewnątrz przestrzeni między obserwacją a jej sąsiadami.
W efekcie powstają realistycznie wyglądające dane, które zwiększają reprezentację klasy mniejszościowej.
| Zalety | Wady |
|---|---|
unika przeuczenia wynikającego z kopiowania danych zachowuje strukturę przestrzeni cech umożliwia lepsze uczenie modeli klasyfikacyjnych |
może generować punkty w obszarach nakładania się klas wymaga odpowiedniego skalowania i czyszczenia danych (braków, outlierów) |
W praktyce w R możemy ta metodę zastosować wykorzystując pakiet smotefamily.
Klasa nie musi być zero-jedynkowa. Smotefamily umożliwia również pracę na zmiennych z więcej niż dwiema klasami.
Argumenty funkcji:
X - macierz lub ramka danych zawierająca zmienne objaśniające (cechy) – bez zmiennej celu,
target - wektor klasyfikacyjny (binarna zmienna celu), np. 0 = majority, 1 = minority,
K - liczba najbliższych sąsiadów.
dup_size - liczba syntetycznych przykładów do wygenerowania w przeliczeniu na jeden oryginalny przypadek z klasy mniejszościowej. Domyślnie algorytm wylicza liczbę syntetycznych przykładów tak, aby klasy były zrównoważone (dup_size = 0).
library(smotefamily)
# Stosujemy SMOTE dla klasy binarnej, usuwamy w locie z ramki
# zmienną reprezentującą klasy.
smote_output <- SMOTE(X = select(train_scaled, -PM10_ex),
target = train_scaled$PM10_ex,
K = 5)
# Nowe dane
train_scaled_smote <- data.frame(smote_output$data)
train_scaled_smote$class <- as.factor(train_scaled_smote$class)
train_scaled_smote <- train_scaled_smote %>%
rename(PM10_ex = class)
table(train_scaled_smote$PM10_ex)
0 1
502 456 I tutaj kilka słów ostrzeżenia…
…jeżeli w naszej ramce danych pojawiają się zmienne dotyczące czasu, to musimy podjąć decyzję, czy je pozostawić / usunąć / przekodować.
Na pytanie czy usuwać można odpowiedzieć następująco:
NIE, jeśli są ważnymi predyktorami
Jeśli zmienne takie jak miesiąc, dzień, rok niosą informację istotną dla klasyfikacji (np. sezonowość chorób, wzorce emisji, aktywność użytkowników), to powinny pozostać w danych przed zastosowaniem SMOTE i będą uwzględnione przy generowaniu syntetycznych punktów.
TAK, usunąć lub zakodować w inny sposób jeżeli:
są identyfikatorami (np. konkretna data), a nie cechami (czyli niosą losową lub nieużyteczną informację),
mają charakter ciągły lub porządkowy, ale ich rozkład jest nietypowy (np. rok = 2020, 2021, 2022),
są skategoryzowane nominalnie, ale nie zostały zakodowane jako czynniki. Mogą wtedy wprowadzać zakłócenia w SMOTE.
Przykładowo zmienną MIESIĄC (istotna z punktu widzenia sezonowości pola imisji oraz emisji) można zakodować z wykorzystaniem dwóch zmiennych MONTH_SIN oraz MONTH_COS
train$MONTH_SIN <- sin(2 * pi * train$MONTH/12)
train$MONTH_COS <- cos(2 * pi * train$MONTH/12)kodujemy w ten sposób zmienną “kołową” i obie z naszych zmiennych wchodzą następnie do procedury SMOTE (przed procedurą usuwamy zmienną MONTH oraz inne związane z czasem: YEAR, DAY).
W przypadku modelowania imisji (stężeń) zanieczyszczeń warto również uwzględnić, czy dany dzień był dniem roboczym.
Oczywiście nic nie stoi na przeszkodzie, aby kalibrować modele dla każdego miesiąca osobno, wówczas nie musimy się przejmować sezonowością.
W celu uproszczenia notacji w ostatnim przykładzie zrównoważyliśmy klasy korzystając ze SMOTE bez wcześniejszych procedur transformacyjnych. Należy o nich pamiętać!
Podsumowując, wydzielenie osobnych zbiorów kalibrującego i testującego to kluczowy krok, który pozwala uczciwie ocenić, jak model będzie działał na nowych danych. Skalowanie pozwala na ujednolicenie skali zmiennych (istotne w niektórych narzędziach uczenia maszynowego). Transformacja pozwala na poprawę rozkładów cech - stają się bardziej zbliżone do rozkładu normalnego. W przypadku nierównowagi klas warto dodatkowo zadbać o odpowiednie zrównoważenie zbioru uczącego, aby model “ucząc się” nie pomijał rzadkich, a często najważniejszych przypadków.
Po więcej usystematyzowanych informacji dotyczących modelowania statystycznego zapraszamy na kursy DataCraft LAB.
Ustawowy limit dobowego stężenia PM10 to 50 \(\mu \text{g/m}^3\), ale w celach dydaktycznych - w kolejnym rozdziale wykorzystamy nasze dane do kalibrowania modeli regresji logistycznej zastosujemy nieco niższy próg, żeby zapewnić sobie nieco większą liczebność klasy wskazującej na wysokie stężenia (nazwijmy ją z lekkim przymrużeniem oka zdarzeniem ekstremalnym)↩︎