[1] "BIAŁYSTOK" "BIELSKO_BIAŁA" "CHOJNICE"
[4] "CZĘSTOCHOWA" "ELBLĄG_MILEJEWO" "GDAŃSK_ŚWIBNO"
[7] "GORZÓW_WIELKOPOLSKI" "HEL" "JELENIA_GÓRA"
[10] "KALISZ" "KASPROWY_WIERCH" "KATOWICE_MUCHOWIEC"
[13] "KĘTRZYN" "KIELCE_SUKÓW" "KŁODZKO"
[16] "KOŁO" "KOŁOBRZEG_DŹWIRZYNO" "KOSZALIN"
[19] "KOZIENICE" "KRAKÓW_BALICE" "KROSNO"
[22] "LEGNICA" "LESKO" "LESZNO"
[25] "LĘBORK" "LUBLIN_RADAWIEC" "ŁEBA"
[28] "ŁÓDŹ_LUBLINEK" "MIKOŁAJKI" "MŁAWA"
[31] "NOWY_SĄCZ" "OLSZTYN" "OPOLE"
[34] "PIŁA" "PŁOCK" "POZNAŃ_ŁAWICA"
[37] "RACIBÓRZ" "RESKO_SMÓLSKO" "RZESZÓW_JASIONKA"
[40] "SANDOMIERZ" "SIEDLCE" "SŁUBICE"
[43] "SULEJÓW" "SUWAŁKI" "SZCZECIN"
[46] "ŚNIEŻKA" "ŚWINOUJŚCIE" "TARNÓW"
[49] "TERESPOL" "TORUŃ" "USTKA"
[52] "WARSZAWA_OKĘCIE" "WIELUŃ" "WŁODAWA"
[55] "WROCŁAW_STRACHOWICE" "ZAKOPANE" "ZAMOŚĆ"
[58] "ZIELONA_GÓRA" 2 Klasyfikacja
Problem do rozwiązania: przedstawienie w postaci graficznej (tzw. dywanik) kwantylowej klasyfikacji średnich miesięcznych wartości temperatury powietrza dla wybranej stacji synoptycznej w Polsce w wieloleciu 1951-2024.
Słowa kluczowe: klasyfikacja kwantylowa, wykresy dywaniki
2.1 Dane
Dane wykorzystane w niniejszej analizie opisano szczegółowo w rozdziale Section 1.1.
Wczytujemy dane i wyświetlamy listę stacji.
Załóżmy, że naszą analizę przeprowadzimy dla stacji Warszawa Okęcie dla okresu 1951-2024. Przygotujmy zatem obiekt data zawierający interesujące nas dane. Poprzedzimy to wczytaniem niezbędnych w naszych obliczeń bibliotek.
library(dplyr)
library(tidyr)
library(ggplot2)data <- t2m_stacje %>%
filter(YEAR >= 1951, STATION == "WARSZAWA_OKĘCIE")Zerknijmy na podsumowanie naszego zbioru.
summary(data) CODE STATION LON LAT
Min. :375 Length:888 Min. :20.96 Min. :52.16
1st Qu.:375 Class :character 1st Qu.:20.96 1st Qu.:52.16
Median :375 Mode :character Median :20.96 Median :52.16
Mean :375 Mean :20.96 Mean :52.16
3rd Qu.:375 3rd Qu.:20.96 3rd Qu.:52.16
Max. :375 Max. :20.96 Max. :52.16
TIME T2M MONTH YEAR
Min. :1951-01-01 Min. :-12.541 Min. : 1.00 Min. :1951
1st Qu.:1969-06-23 1st Qu.: 1.965 1st Qu.: 3.75 1st Qu.:1969
Median :1987-12-16 Median : 8.485 Median : 6.50 Median :1988
Mean :1987-12-16 Mean : 8.457 Mean : 6.50 Mean :1988
3rd Qu.:2006-06-08 3rd Qu.: 15.768 3rd Qu.: 9.25 3rd Qu.:2006
Max. :2024-12-01 Max. : 22.893 Max. :12.00 Max. :2024 Wszystko wygląda OK.
2.2 Klasyfikacja kwantylowa
Przeprowadzenie klasyfikacji kwantylowej opiera się o wartości graniczne. W przypadku klasyfikacji kwantylowej wartości te są wyznaczane jako wybrane kwantyle z okresu uznawanego za tzw. okres normalny, w naszym przypadku będzie to 30-letni okres 1991-2020.
Załóżmy, że docelowa liczba klas będzie wynosić 5 i będzie wyznaczana przez kwantyle: 10%, 40%, 60% oraz 90%, odpowiadających wartościom o określonym prawdopodobieństwie przekroczenia (odpowiednio: 90, 60, 40 oraz 10%).
Przebieg temperatury charakteryzuje się wyraźnym cyklem rocznym
ggplot(data, aes(x = TIME, y = T2M))+
geom_line()+
theme_bw()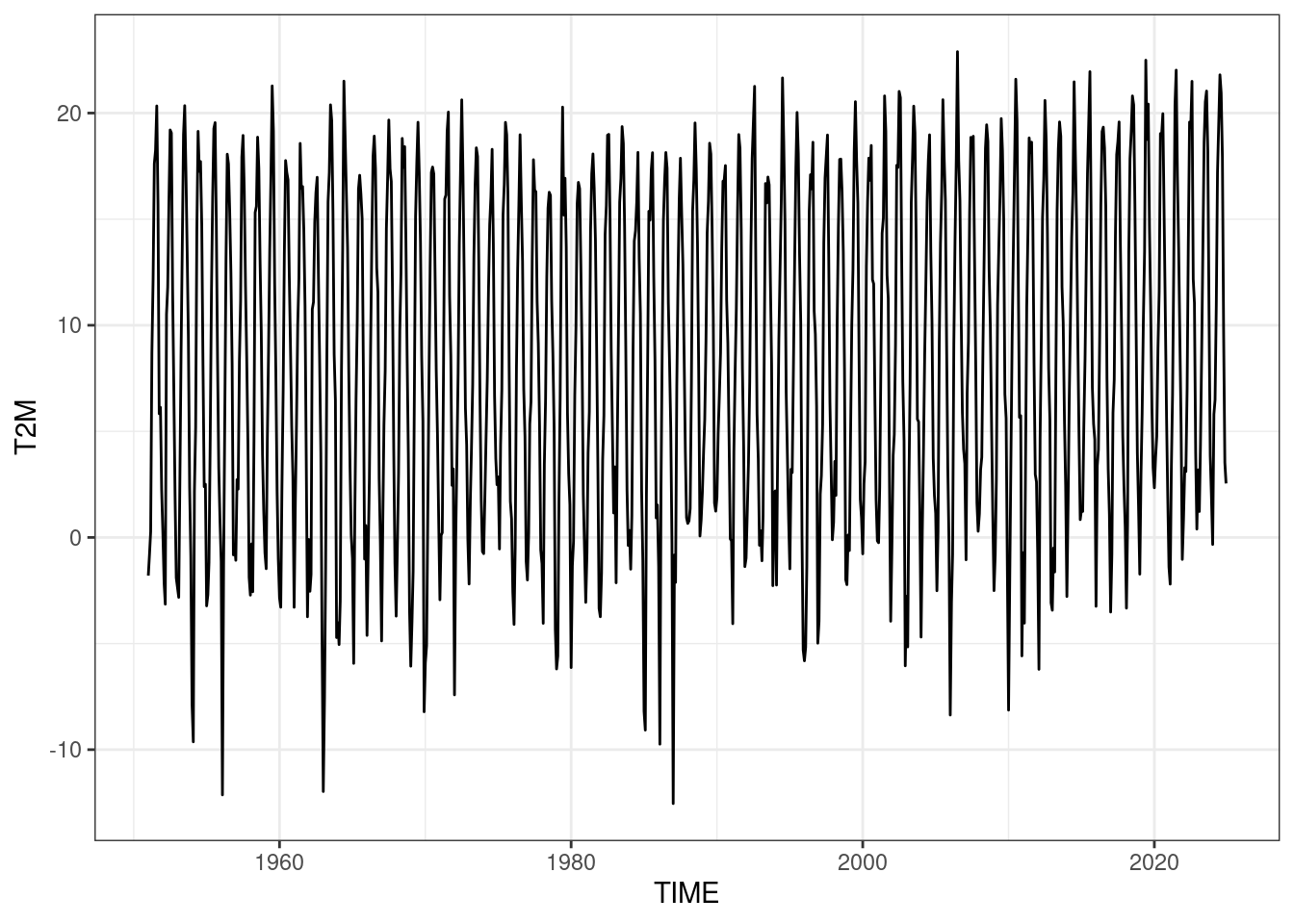
dlatego wartości kwantyli należy obliczać dla każdego miesiąca oddzielnie.
Wykonajmy obliczenia
kwantyle <- data %>%
filter(YEAR >= 1991, YEAR <=2020) %>%
group_by(MONTH) %>%
summarise(Q10 = quantile(T2M, probs = 0.1),
Q40 = quantile(T2M, probs = 0.4),
Q60 = quantile(T2M, probs = 0.6),
Q90 = quantile(T2M, probs = 0.9))
kwantyle# A tibble: 12 × 5
MONTH Q10 Q40 Q60 Q90
<dbl> <dbl> <dbl> <dbl> <dbl>
1 1 -4.81 -1.58 -0.315 1.40
2 2 -4.17 -0.908 0.641 3.39
3 3 0.153 3.15 3.95 5.82
4 4 7.43 9.03 9.28 10.9
5 5 12.6 13.8 14.3 15.9
6 6 15.9 17.3 17.9 19.0
7 7 17.7 19.2 19.9 21.5
8 8 17.8 18.6 18.9 20.5
9 9 12.1 13.4 14.5 15.7
10 10 6.35 8.09 9.49 10.7
11 11 1.48 3.79 4.98 5.93
12 12 -5.01 0.132 1.19 2.68Mamy policzone kwantyle, teraz przyszedł czas na połączenie ranki data z ramką kwantyle, żebyśmy mogli przypisać klasy dla poszczególnych miesięcy z wielolecia 1951-2024 do klas, które za chwilę zdefiniujemy.
data <- data %>%
left_join(kwantyle, by = "MONTH")head(data) CODE STATION LON LAT TIME T2M MONTH YEAR
1 375 WARSZAWA_OKĘCIE 20.96111 52.16278 1951-01-01 -1.7980615 1 1951
2 375 WARSZAWA_OKĘCIE 20.96111 52.16278 1951-02-01 -0.7539331 2 1951
3 375 WARSZAWA_OKĘCIE 20.96111 52.16278 1951-03-01 0.2700537 3 1951
4 375 WARSZAWA_OKĘCIE 20.96111 52.16278 1951-04-01 8.6964758 4 1951
5 375 WARSZAWA_OKĘCIE 20.96111 52.16278 1951-05-01 12.1584814 5 1951
6 375 WARSZAWA_OKĘCIE 20.96111 52.16278 1951-06-01 17.6149023 6 1951
Q10 Q40 Q60 Q90
1 -4.8050623 -1.5780420 -0.3151270 1.399906
2 -4.1730280 -0.9075464 0.6413977 3.393629
3 0.1525366 3.1496985 3.9524756 5.824409
4 7.4310858 9.0326086 9.2822241 10.873441
5 12.5506262 13.7827429 14.3471777 15.899308
6 15.8664160 17.3082129 17.8625586 19.043540Mamy przygotowane dane do klasyfikacji.
Przyjmijmy następujące nazwy miesięcy dla klas definiowanych przez wartości kwantyli
T2M <= Q10 - EKSTREMALNIE CHŁODNY
Q10 < T2M <= Q40 - CHŁODNY
Q40 < T2M <= Q60 - NORMALNY
Q60 < T2M <= Q90 - CIEPŁY
T2M > Q90 - EKSTREMALNIE CIEPŁY
Teraz wykorzystamy funkcję case_when() żeby dokonać klasyfikacji dla wszystkich wierszy naszej ramki danych. Klasy są prawostronnie domknięte.
data <- data %>%
mutate(CLASS = case_when(
T2M <=Q10 ~ "EKSTREMALNIE CHŁODNY",
T2M > Q10 & T2M <=Q40 ~ "CHŁODNY",
T2M > Q40 & T2M <=Q60 ~ "NORMALNY",
T2M > Q60 & T2M <=Q90 ~ "CIEPŁY",
T2M > Q90 ~ "EKSTREMANIE CIEPŁY"))Właśnie zaklasyfikowaliśmy nasze miesiące do poszczególnych klas.
2.3 Wykresy
Teraz przygotujmy wykres na podstawie naszych obliczeń.
ggplot(data, aes(x = MONTH, y = YEAR, fill = CLASS))+
geom_tile()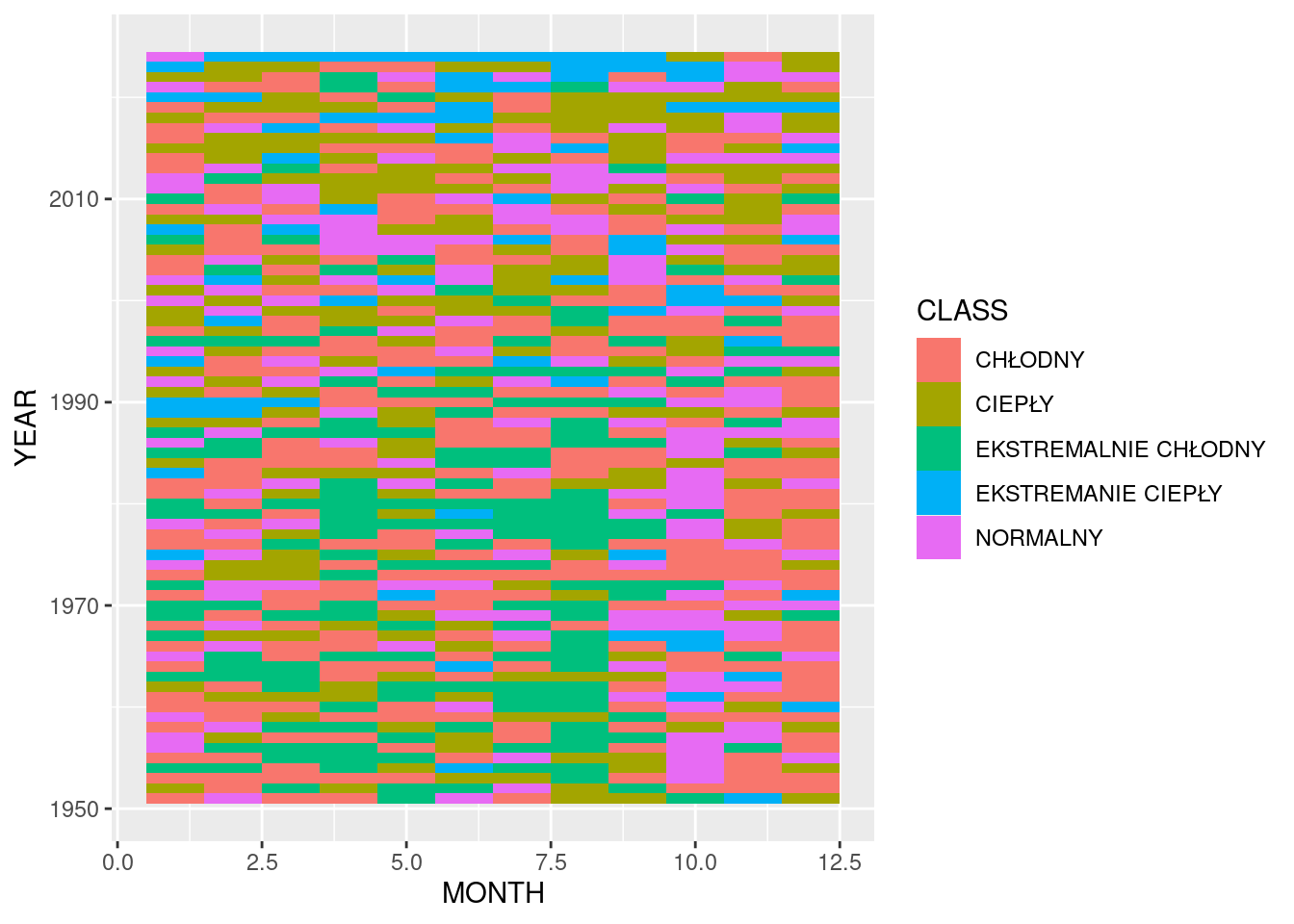
Wykres powstał, ale jest kilka elementów, które wymagają uwagi:
kolejność lat - trzeba ją odwrócić
miesiące - trzeba przedstawić jako liczby całkowite
kolejność klas - jest alfabetycznie powinna być według natężania zjawiska
skala kolorystyczna - powinna być tzw. divergent scale
Najpierw porządek w klasach
data$CLASSord <- factor(data$CLASS, levels = c("EKSTREMALNIE CHŁODNY", "CHŁODNY", "NORMALNY", "CIEPŁY", "EKSTREMANIE CIEPŁY"))I powtórnie wykres, tym razem już ze zmienną CLASSord jako punkt odniesienia mapowania fill, zmienioną kolejnością lat oraz poprawnie oznaczonymi miesiącami na osi X. Ddodajmy również ramki do poszczególnych komórek.
Odrobina własnego stylu.
my_style <- theme(text = element_text(size = 14),
panel.border = element_rect(colour = "black", fill = NA, linewidth = 1))ggplot(data, aes(x = as.factor(MONTH), y = YEAR, fill = CLASSord))+
geom_tile(color = "black")+
labs(
title = "Klasyfikacja termiczna średniej miesięcznej temperatury powietrza",
subtitle = "Warszawa Okęcie, 1951-2024",
caption = "źródło danych: ERA5",
fill = "Klasa",
x = "Miesiąc",
y = "Rok"
)+
scale_y_reverse()+
theme_bw()+
my_style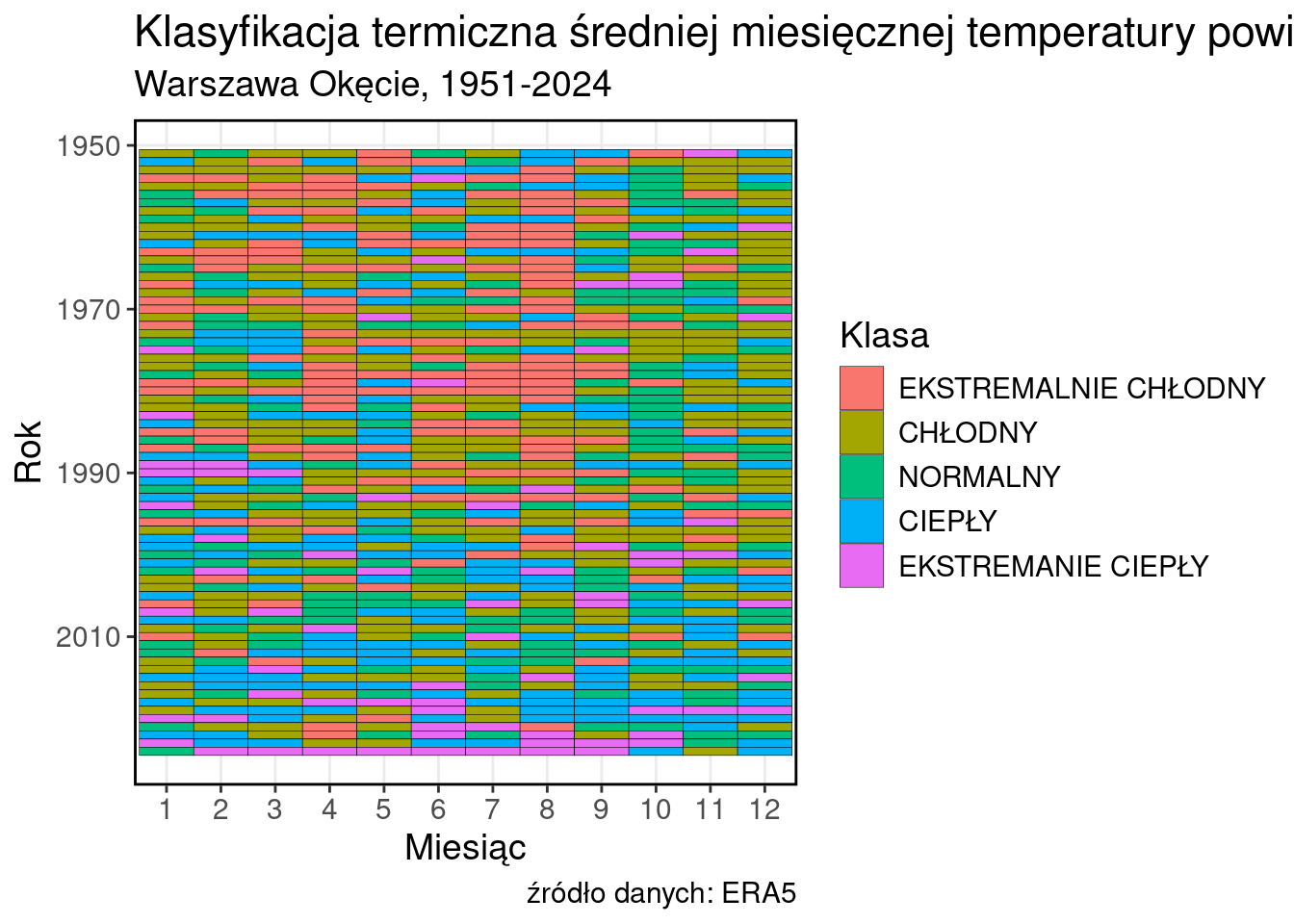
I na końcu robimy porządek ze skalą kolorów.
Ładujemy bibliotekę, która dobrze współpracuje z kolorami viridis
library(viridis)Ładowanie wymaganego pakietu: viridisLiteggplot(data, aes(x = as.factor(MONTH), y = YEAR, fill = CLASSord))+
geom_tile(color = "black")+
labs(
title = "Klasyfikacja termiczna średniej miesięcznej temperatury powietrza",
subtitle = "Warszawa Okęcie, 1951-2024",
caption = "źródło danych: ERA5",
fill = "Klasa",
x = "Miesiąc",
y = "Rok"
)+
scale_y_reverse(breaks = seq(1950, 2025, 5))+
theme_bw()+
scale_fill_viridis_d()+
my_style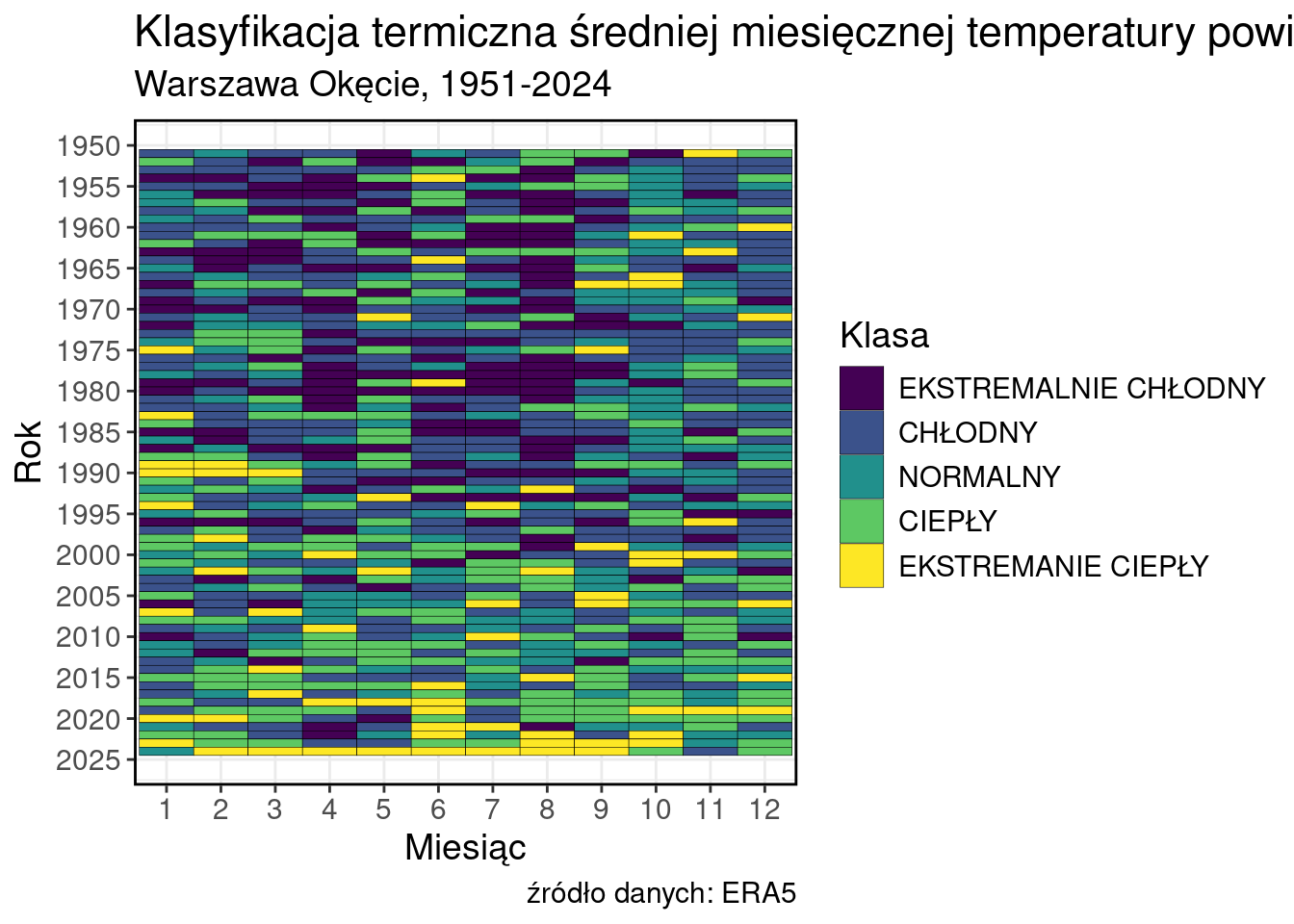
Jest OK, ale skala barw powinna być “rozbieżna”. Zdefiniujmy zatem kolory korzystając z dosyć wszechstronnej biblioteki RColorBrewer.
library(RColorBrewer)moje_kolory <- colorRampPalette(c("navyblue", "white", "red"))(5)ggplot(data, aes(x = as.factor(MONTH), y = YEAR, fill = CLASSord))+
geom_tile(color = "black")+
labs(
title = "Klasyfikacja termiczna średniej miesięcznej temperatury powietrza",
subtitle = "Warszawa Okęcie, 1951-2024 (okres referencyjny: 1991-2020)",
caption = "źródło danych: ERA5",
fill = "Klasa",
x = "Miesiąc",
y = "Rok"
)+
scale_y_reverse(breaks = seq(1950, 2025, 5))+
theme_bw()+
scale_fill_manual(values = moje_kolory)+
my_style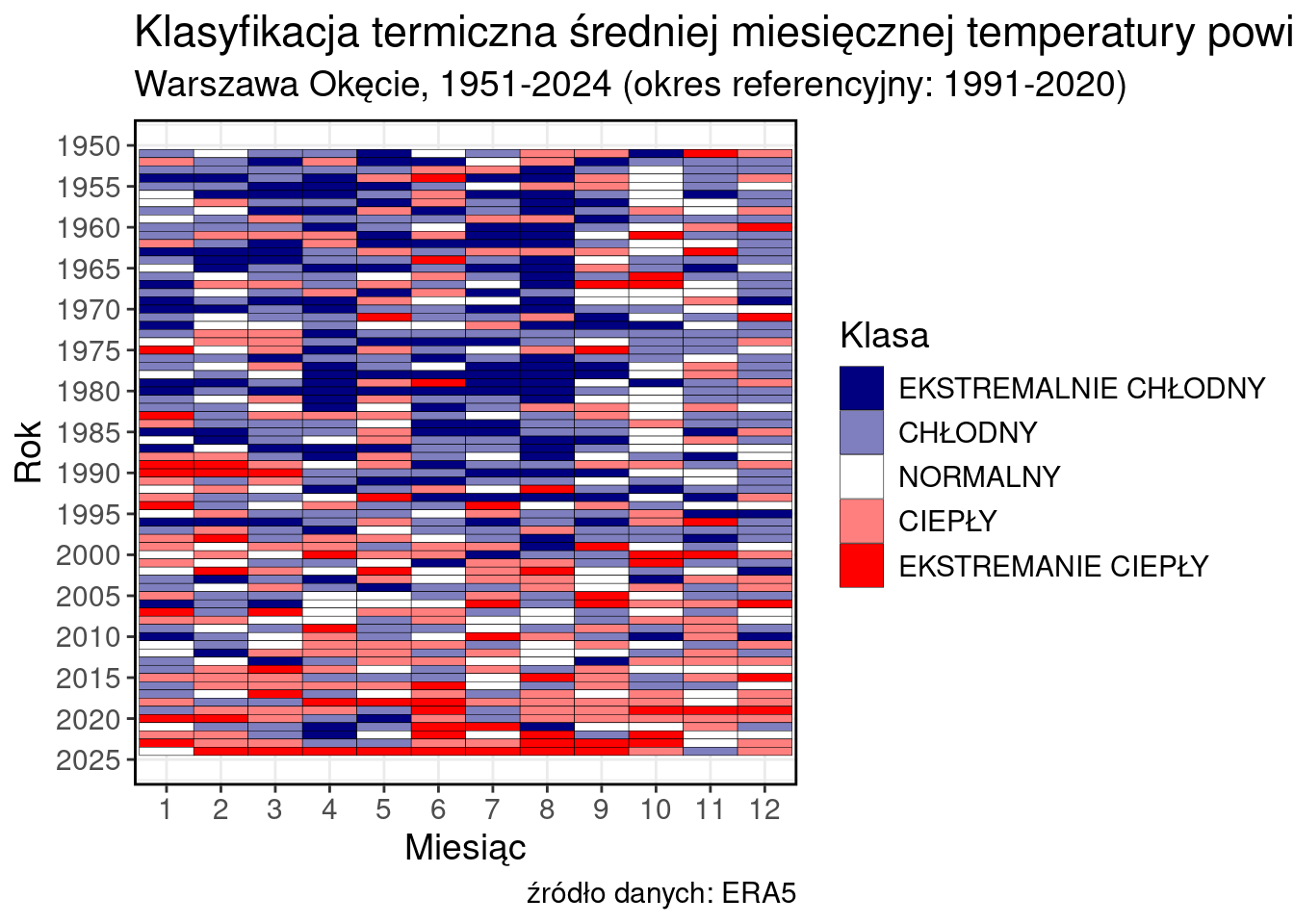
Eksportujemy wykres.
ggsave(filename = "klasyfikacja.jpg",
dpi = 300,
width = 10,
height = 14,
units = "in")Finalny wykres wygląda następująco:
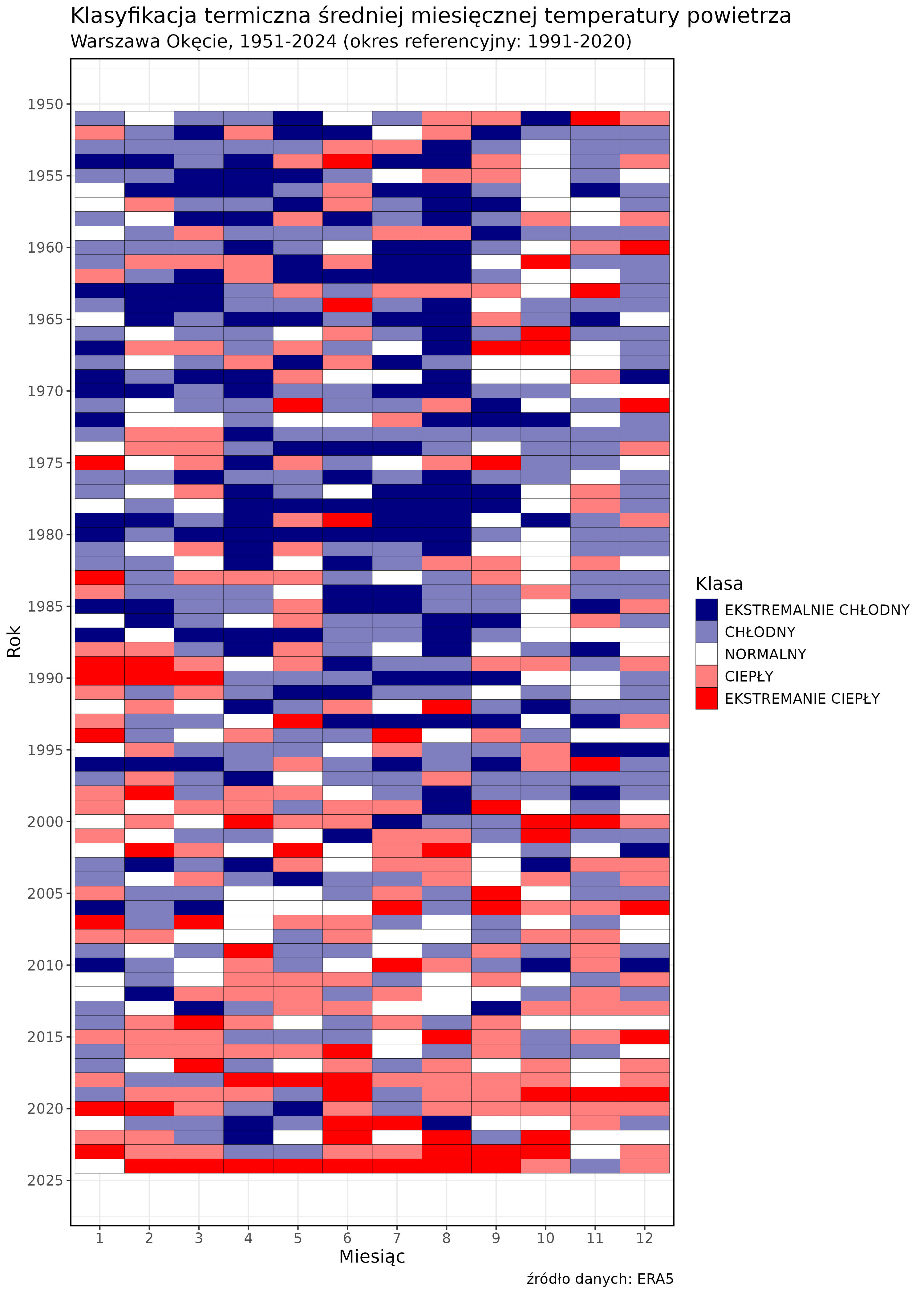
Legendę można jeszcze przenieść na dół wykresu.
ggplot(data, aes(x = as.factor(MONTH), y = YEAR, fill = CLASSord))+
geom_tile(color = "black")+
labs(
title = "Klasyfikacja termiczna średniej miesięcznej temperatury powietrza",
subtitle = "Warszawa Okęcie, 1951-2024 (okres referencyjny: 1991-2020)",
caption = "źródło danych: ERA5",
fill = "Klasa",
x = "Miesiąc",
y = "Rok"
)+
scale_y_reverse(breaks = seq(1950, 2025, 5))+
theme_bw()+
scale_fill_manual(values = moje_kolory)+
theme(legend.position = "bottom")+
my_style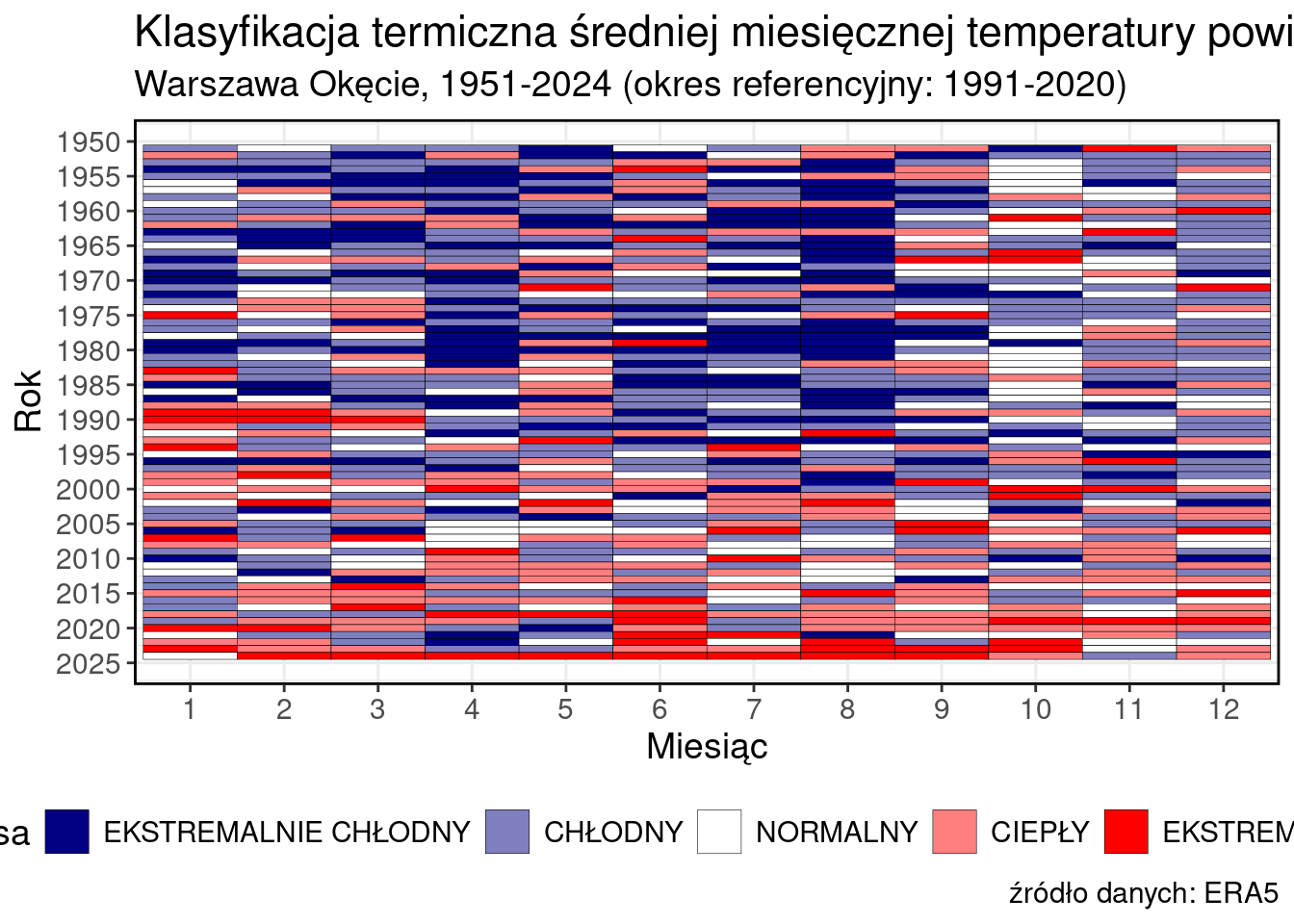
ggsave(filename = "klasyfikacja_a.jpg",
dpi = 300,
width = 10,
height = 14,
units = "in")I wówczas będzie on wyglądał następująco:
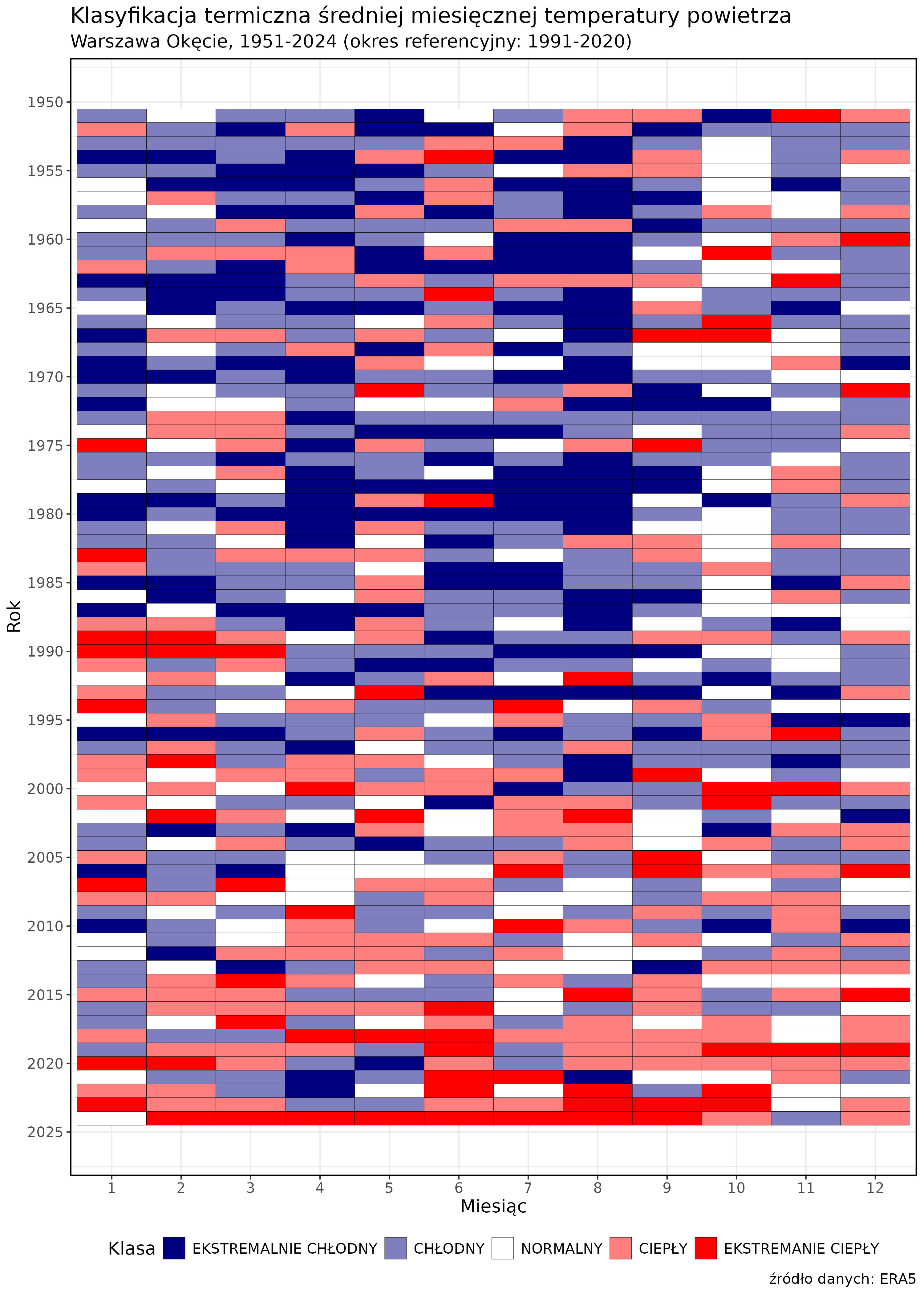
Powyższe stanowi jedynie wycinek możliwości R, heatmapy można np. uzupełnić o wartości absolutne lub anomalii.
Po więcej zapraszamy na kursy DataCraft LAB.