library(dplyr)
library(tidyr)
library(ggplot2)1 Trend
Problem do rozwiązania: obliczenie współczynników kierunkowych równania trendu oraz określenie ich istotności statystycznej dla temperatury powietrza w skali miesięcznej dla wybranych stacji synoptycznych w Polsce w latach 1951-2024
Słowa kluczowe: trend, istotność statystyczna, wykresy złożone
1.1 Dane
Dane pochodzą z Reanalizy ERA5 (Copernicus Climate Change Service 2019) i zawierają średnie miesięczne wartości wybranych elementów meteorologicznych. W przypadku niniejszej analizy jest to temperatura powietrza na poziomie 2m n.p.g. Rozdzielczość przestrzenna ERA5 to 0,25x0,25 stopnia długości/szerokości geograficznej. Serie danych dla poszczególnych stacji są wartościami z najbliższego im punktu grid reanalizy.
Dane zostały zapisane w natywnym formacie R: “rda” i są w podkatalogu data - stąd dodatkowy element kodu wskazujący na lokalizację pliku z danymi
Plik można pobrać TUTAJ
Załadujmy zatem biblioteki i dane
load("data/t2m_stacje.rda")Zerknijmy na listę zmiennych
names(t2m_stacje)[1] "CODE" "STATION" "LON" "LAT" "TIME" "T2M" "MONTH"
[8] "YEAR" I strukturę danych
str(t2m_stacje)'data.frame': 52200 obs. of 8 variables:
$ CODE : num 295 295 295 295 295 295 295 295 295 295 ...
$ STATION: chr "BIAŁYSTOK" "BIAŁYSTOK" "BIAŁYSTOK" "BIAŁYSTOK" ...
$ LON : num 23.2 23.2 23.2 23.2 23.2 ...
$ LAT : num 53.1 53.1 53.1 53.1 53.1 ...
$ TIME : Date, format: "1950-01-01" "1950-02-01" ...
$ T2M : num -10.95 -0.42 1.66 9.66 14.34 ...
$ MONTH : num 1 2 3 4 5 6 7 8 9 10 ...
$ YEAR : num 1950 1950 1950 1950 1950 1950 1950 1950 1950 1950 ...CODE to 3 cyfrowy kod stacji synoptycznej w sieci IMGW-PIB
STATION - nazwa stacji
LON - długość geograficzna
LAT - szerokość geograficzna
TIME - data
T2M - średnia miesięczna temperatura powietrza
MONTH - miesiąc
YEAR - rok
Do analizy wybierzemy kilka stacji, ale najpierw zerknijmy jakie stacje mamy do dyspozycji
unique(t2m_stacje$STATION) [1] "BIAŁYSTOK" "BIELSKO_BIAŁA" "CHOJNICE"
[4] "CZĘSTOCHOWA" "ELBLĄG_MILEJEWO" "GDAŃSK_ŚWIBNO"
[7] "GORZÓW_WIELKOPOLSKI" "HEL" "JELENIA_GÓRA"
[10] "KALISZ" "KASPROWY_WIERCH" "KATOWICE_MUCHOWIEC"
[13] "KĘTRZYN" "KIELCE_SUKÓW" "KŁODZKO"
[16] "KOŁO" "KOŁOBRZEG_DŹWIRZYNO" "KOSZALIN"
[19] "KOZIENICE" "KRAKÓW_BALICE" "KROSNO"
[22] "LEGNICA" "LESKO" "LESZNO"
[25] "LĘBORK" "LUBLIN_RADAWIEC" "ŁEBA"
[28] "ŁÓDŹ_LUBLINEK" "MIKOŁAJKI" "MŁAWA"
[31] "NOWY_SĄCZ" "OLSZTYN" "OPOLE"
[34] "PIŁA" "PŁOCK" "POZNAŃ_ŁAWICA"
[37] "RACIBÓRZ" "RESKO_SMÓLSKO" "RZESZÓW_JASIONKA"
[40] "SANDOMIERZ" "SIEDLCE" "SŁUBICE"
[43] "SULEJÓW" "SUWAŁKI" "SZCZECIN"
[46] "ŚNIEŻKA" "ŚWINOUJŚCIE" "TARNÓW"
[49] "TERESPOL" "TORUŃ" "USTKA"
[52] "WARSZAWA_OKĘCIE" "WIELUŃ" "WŁODAWA"
[55] "WROCŁAW_STRACHOWICE" "ZAKOPANE" "ZAMOŚĆ"
[58] "ZIELONA_GÓRA" przetwórzmy naszą ramkę danych tak, aby zawierała informacje jedynie dla stacji: ŁEBA, KRAKÓW_BALICE, MIKOŁAJKI, WROCŁAW_STRACHOWICE, ZAMOŚĆ.
Wybierzmy również okres rozpoczynający się od roku 1951.
Zapiszmy nasze dane do dalszych analiz jako data.
data <- t2m_stacje %>%
filter(STATION %in% c("ŁEBA", "KRAKÓW_BALICE", "MIKOŁAJKI", "WROCŁAW_STRACHOWICE", "ZAMOŚĆ")) %>%
filter(YEAR >= 1951)I ponownie sprawdźmy czy wybraliśmy stacje i poprawny zakres lat.
unique(data$STATION)[1] "KRAKÓW_BALICE" "ŁEBA" "MIKOŁAJKI"
[4] "WROCŁAW_STRACHOWICE" "ZAMOŚĆ" range(data$YEAR)[1] 1951 2024Wygląda OK
Teraz jeszcze szybki wykres dla sprawdzenia, czy np. dla stacji w Łebie można wykreślić przebieg temperatury powietrza dla miesiąca stycznia.
ggplot(data = filter(data, STATION == "ŁEBA", MONTH == 1), aes(x = YEAR, y = T2M)) +
geom_line() +
labs(title = "Przebieg średniej miesięcznej (I) temperatury powietrza w Łebie 1951-2024",
x = "ROK",
y = "°C") +
theme_bw()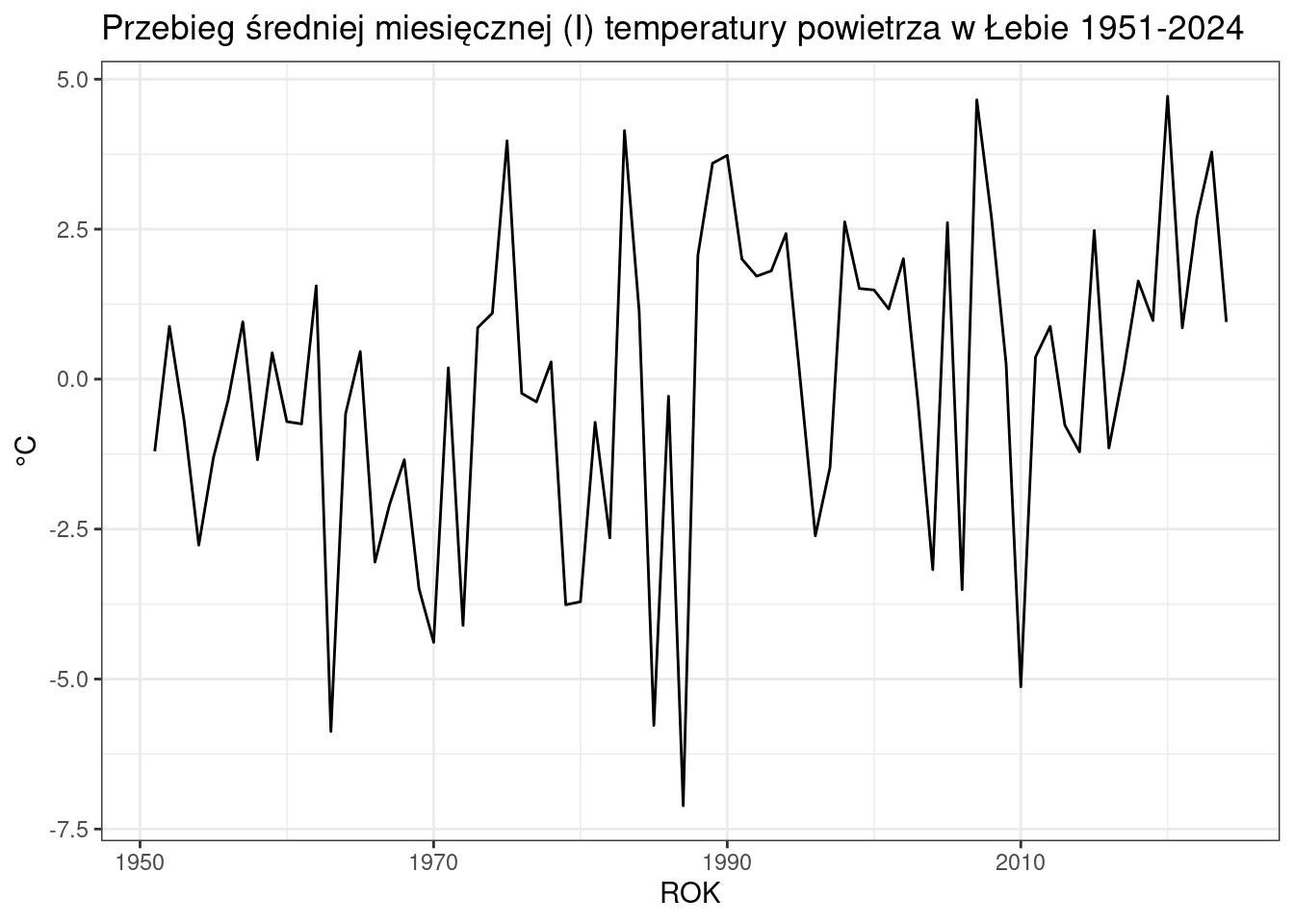
Wygląda na to że dane są przygotowane.
1.2 Trend - funkcja lm()
Analiza trendu w swoim podstawowym wymiarze opiera się na dopasowaniu współczynników równania regresji liniowej do danych, gdzie zmienną niezależną będzie YEAR a zmienną zależną T2M.
Funkcją w R służącą temu celowi jest funkcja lm().
Obliczmy współczynnik kierunkowy równania trendu dla danych, które przed chwilą wyświetliliśmy w postaci wykresu.
Najpierw przygotujmy dane ze stycznia dla Łeby.
leba_sty <- data %>%
filter(STATION == "ŁEBA", MONTH == 1)head(leba_sty) CODE STATION LON LAT TIME T2M MONTH YEAR
1 120 ŁEBA 17.53472 54.75361 1951-01-01 -1.2023584 1 1951
2 120 ŁEBA 17.53472 54.75361 1952-01-01 0.8793677 1 1952
3 120 ŁEBA 17.53472 54.75361 1953-01-01 -0.6892358 1 1953
4 120 ŁEBA 17.53472 54.75361 1954-01-01 -2.7662622 1 1954
5 120 ŁEBA 17.53472 54.75361 1955-01-01 -1.3054468 1 1955
6 120 ŁEBA 17.53472 54.75361 1956-01-01 -0.3464014 1 1956Tak jak już wcześniej wspomniano obliczenie współczynników równania trendu opiera się na wykorzystaniu regresji liniowej.
Stwórzmy zatem model: trend
trend <- lm(T2M~YEAR, data = leba_sty)I wyświetlmy podsumowanie
summary(trend)
Call:
lm(formula = T2M ~ YEAR, data = leba_sty)
Residuals:
Min 1Q Median 3Q Max
-7.006 -1.352 0.323 1.627 4.538
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -76.24606 26.75131 -2.850 0.00570 **
YEAR 0.03832 0.01346 2.847 0.00574 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.473 on 72 degrees of freedom
Multiple R-squared: 0.1012, Adjusted R-squared: 0.08871
F-statistic: 8.106 on 1 and 72 DF, p-value: 0.005745Wartość współczynnika kierunkowego równania trendu wynosi 0,03832°C / rok. Zazwyczaj wyraża się go na dekadę, tak więc w tym wypadku byłoby to 0,38°C/10 lat.
Szczegółowe omówienie informacji zawartych powyżej wykracza poza ramy niniejszego posta, niemniej jednak warto zwrócić uwagę na jeszcze dwa elementy, a mianowicie Pr(>|t|) dla zmiennej niezależnej YEAR oraz p-value w podsumowaniu. Są to wartości wskazujące na istotność statystyczną równania trendu, a w przypadku regresji prostej (a analiza trendu takową jest) mają one te same wartości. Prawdopodobieństwo popełnienia błędu I-go rodzaju jest niższe niż 0,05, wiec mamy podstawy do odrzucenia hipotezy zerowej stwierdzającej, że wartość współczynnika kierunkowego trendu wynosi 0.
Podkreślam, analiza trendu bez analizy istotności statystycznej jest w zasadzie nieuprawniona.
Wspominam o tych wartościach ponieważ za chwilę będziemy je wykorzystywać w naszej analizie. Aby tego dokonać, wykorzystamy fakt, że struktura obiektu generowanego przez funkcję summary zawiera element coefficients, z którego możemy pobrać wartości p-value.
W przypadku regresji wielokrotnej, sytuacja jest nieco bardziej skomplikowana i trzeba tą procedurę przeprowadzić w dwóch krokach. Najpierw “odczytać” wartości statystyki testowej F, a następnie, posługując się rozkładem F, określić p-value.
Pobierzmy zatem wartości współczynnika kierunkowego oraz p-value z obiektu trend.
współczynnik kierunkowy
trend_coeff <- trend$coefficients[2]
trend_coeff YEAR
0.0383195 oraz p-value
summary(trend)$coefficients Estimate Std. Error t value Pr(>|t|)
(Intercept) -76.2460593 26.751312 -2.850180 0.005695335
YEAR 0.0383195 0.013459 2.847128 0.005744556Nasze p-value jest w 2gim wierszu i czwartej kolumnie tak więc można to zapisać jako:
p_value <- summary(trend)$coefficients[2, 4]
p_value[1] 0.0057445561.3 Obliczenia i wykresy
Skoro już wiemy, jak obliczyć współczynniki kierunkowe trendu oraz zweryfikować jego istotność statystyczną, napiszmy kod, który będzie liczył współczynniki kierunkowe dla wszystkich wybranych przez nas stacji i 12 miesięcy.
Posłużymy się tutaj możliwościami pakietu “dplyr” i przetwarzania potokowego. Dodatkowo wartości współczynnika kierunkowego przemnożymy przez 10, uzyskując przeciętną zmianę wartości temperatury na dekadę.
wspolczynniki <- data %>%
group_by(STATION, MONTH) %>%
summarise(COEFF = lm(T2M~YEAR)$coefficients[2]*10)`summarise()` has grouped output by 'STATION'. You can override using the
`.groups` argument.head(wspolczynniki, n = 15)# A tibble: 15 × 3
# Groups: STATION [2]
STATION MONTH COEFF
<chr> <dbl> <dbl>
1 KRAKÓW_BALICE 1 0.554
2 KRAKÓW_BALICE 2 0.708
3 KRAKÓW_BALICE 3 0.575
4 KRAKÓW_BALICE 4 0.320
5 KRAKÓW_BALICE 5 0.245
6 KRAKÓW_BALICE 6 0.290
7 KRAKÓW_BALICE 7 0.340
8 KRAKÓW_BALICE 8 0.391
9 KRAKÓW_BALICE 9 0.216
10 KRAKÓW_BALICE 10 0.252
11 KRAKÓW_BALICE 11 0.260
12 KRAKÓW_BALICE 12 0.318
13 MIKOŁAJKI 1 0.389
14 MIKOŁAJKI 2 0.627
15 MIKOŁAJKI 3 0.573Jeżeli mamy już obliczone współczynniki to przygotujmy wykres, na którym wyświetlimy te wartości.
Na początek dla każdej stacji przygotujemy wykres z przebiegiem rocznym wartości współczynników kierunkowych równania trendu.
ggplot(wspolczynniki, aes(x = as.factor(MONTH), y = COEFF))+
geom_point()+
labs(
title = "Współczynniki kierunkowe równania trendu",
x = "Miesiąc",
y = "°C / 10 lat"
)+
facet_wrap(~STATION, ncol = 2)+
theme_bw()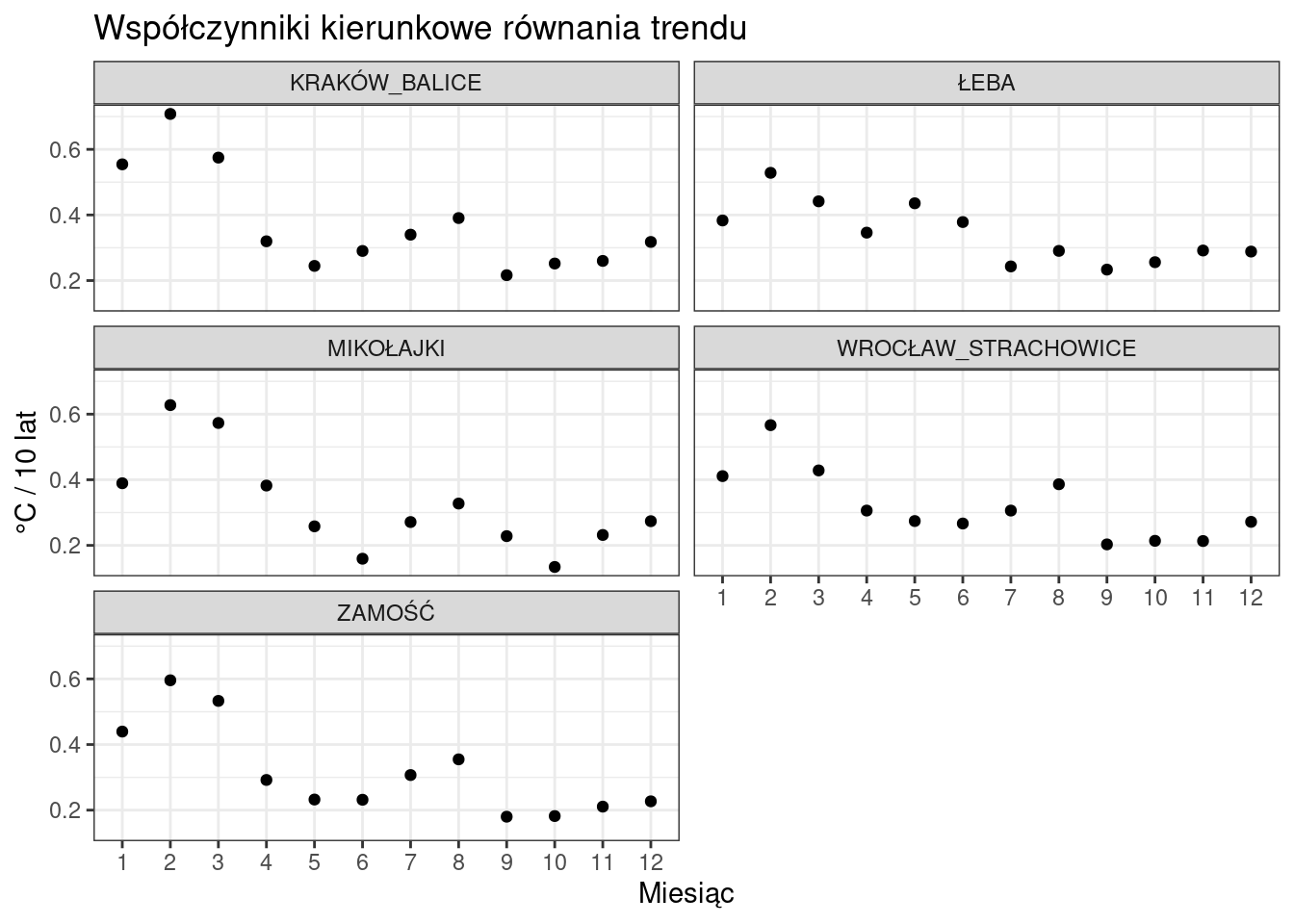
A teraz porównajmy miesiące ale z naciskiem położonym na różnice miedzy stacjami.
ggplot(wspolczynniki, aes(x = STATION, y = COEFF))+
geom_point()+
labs(
title = "Współczynniki kierunkowe równania trendu",
x = "Miesiąc",
y = "°C / 10 lat"
)+
facet_wrap(~MONTH, ncol = 3)+
theme_bw()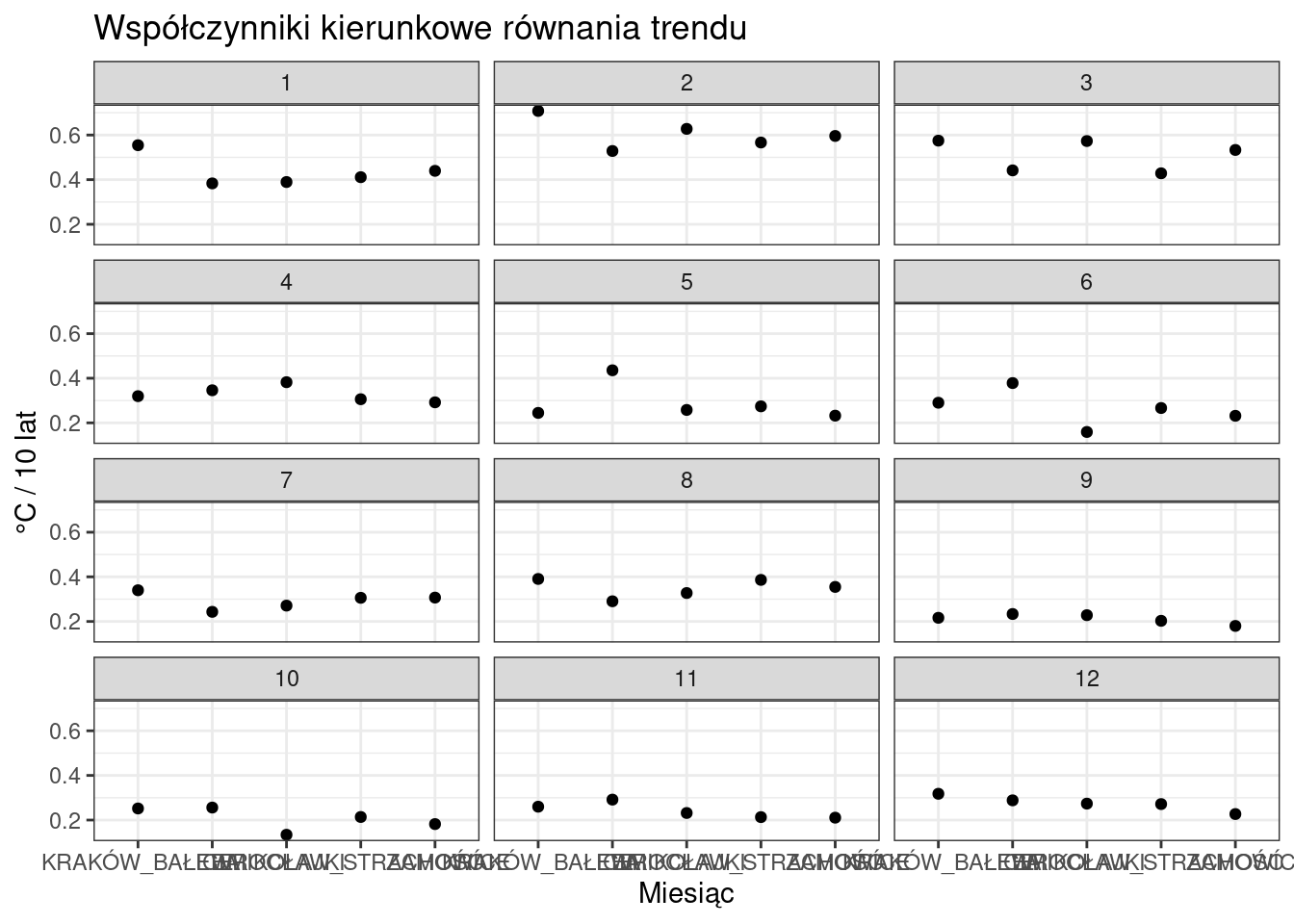
Z wielu względów nie wygląda to zbyt ładnie. Akurat w tym przypadku można temu łatwo zaradzić “wymieniając” osie funkcją coord_flip()
ggplot(wspolczynniki, aes(x = STATION, y = COEFF))+
geom_point()+
labs(
title = "Współczynniki kierunkowe równania trendu",
x = "Stacja",
y = "°C / 10 lat"
)+
facet_wrap(~MONTH, ncol = 3)+
theme_bw()+
coord_flip()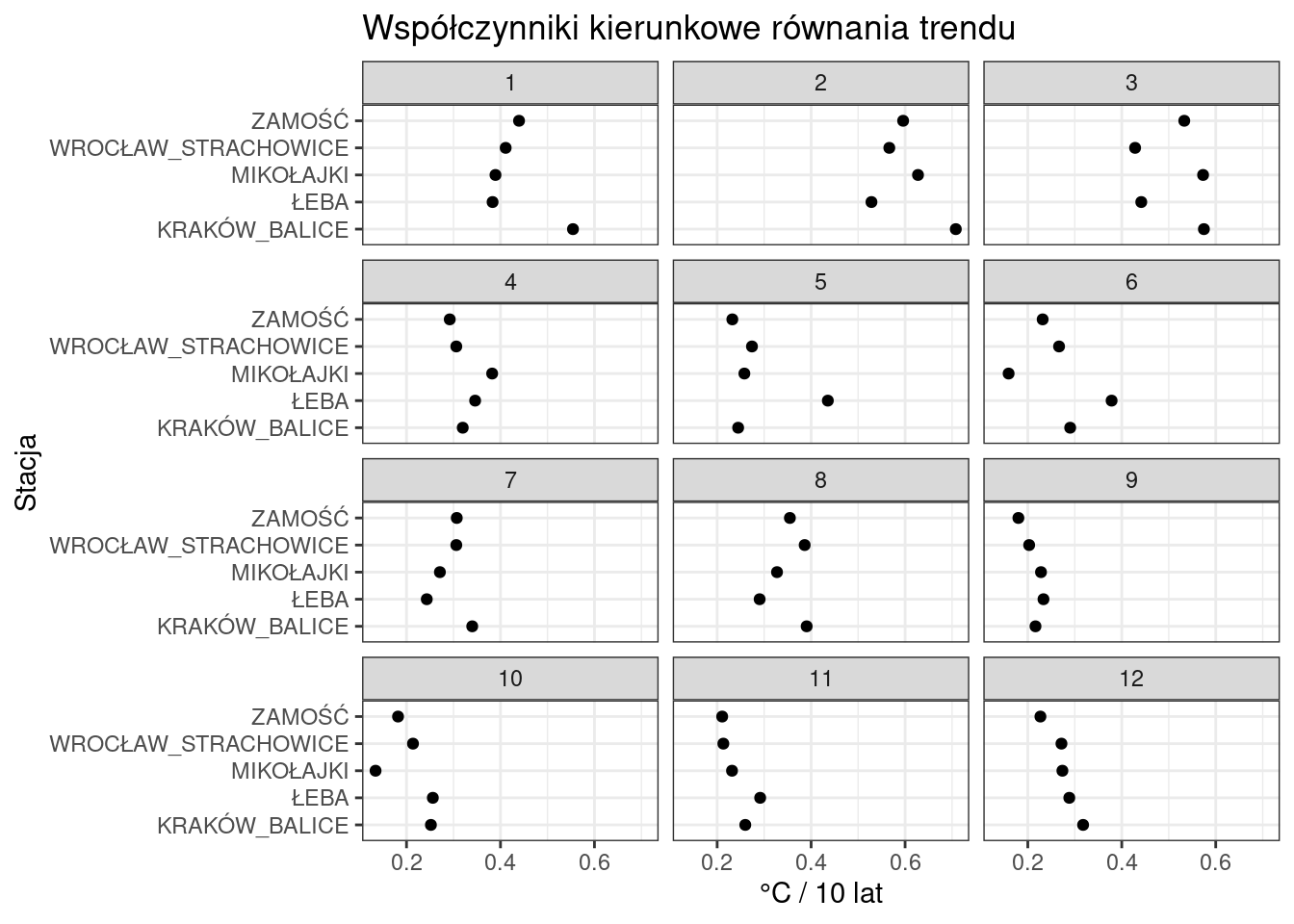
Ok wygląda o wiele lepiej…
Niemniej jednak, gdybym patrzył na to z punktu widzenia klimatologa, to można byłoby wprowadzić jeszcze jedną zmianę - ułożyć miesiące porami roku. Czyli 12, 1, 2 później 3, 4, 5… itd…
Przy ustalaniu kolejności wykresów ggplot2 ustawia je alfabetycznie lub, jak to ma miejsce w tym wypadku, w kolejności rosnącej. Aby to zmienić trzeba zmienić typ zmiennej z liczbowej na czynnik (factor), ustawiając żądaną kolejność.
Najpierw do wynikowej ramki danych dodamy zmienną MONTHord
wspolczynniki$MONTHord <- factor(wspolczynniki$MONTH, levels = c(12, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11))I po drobnej zmianie w kodzie nasz wykres będzie wyglądał następująco
ggplot(wspolczynniki, aes(x = STATION, y = COEFF))+
geom_point()+
labs(
title = "Współczynniki kierunkowe równania trendu",
x = "Stacja",
y = "°C / 10 lat"
)+
facet_wrap(~MONTHord, ncol = 3)+
theme_bw()+
coord_flip()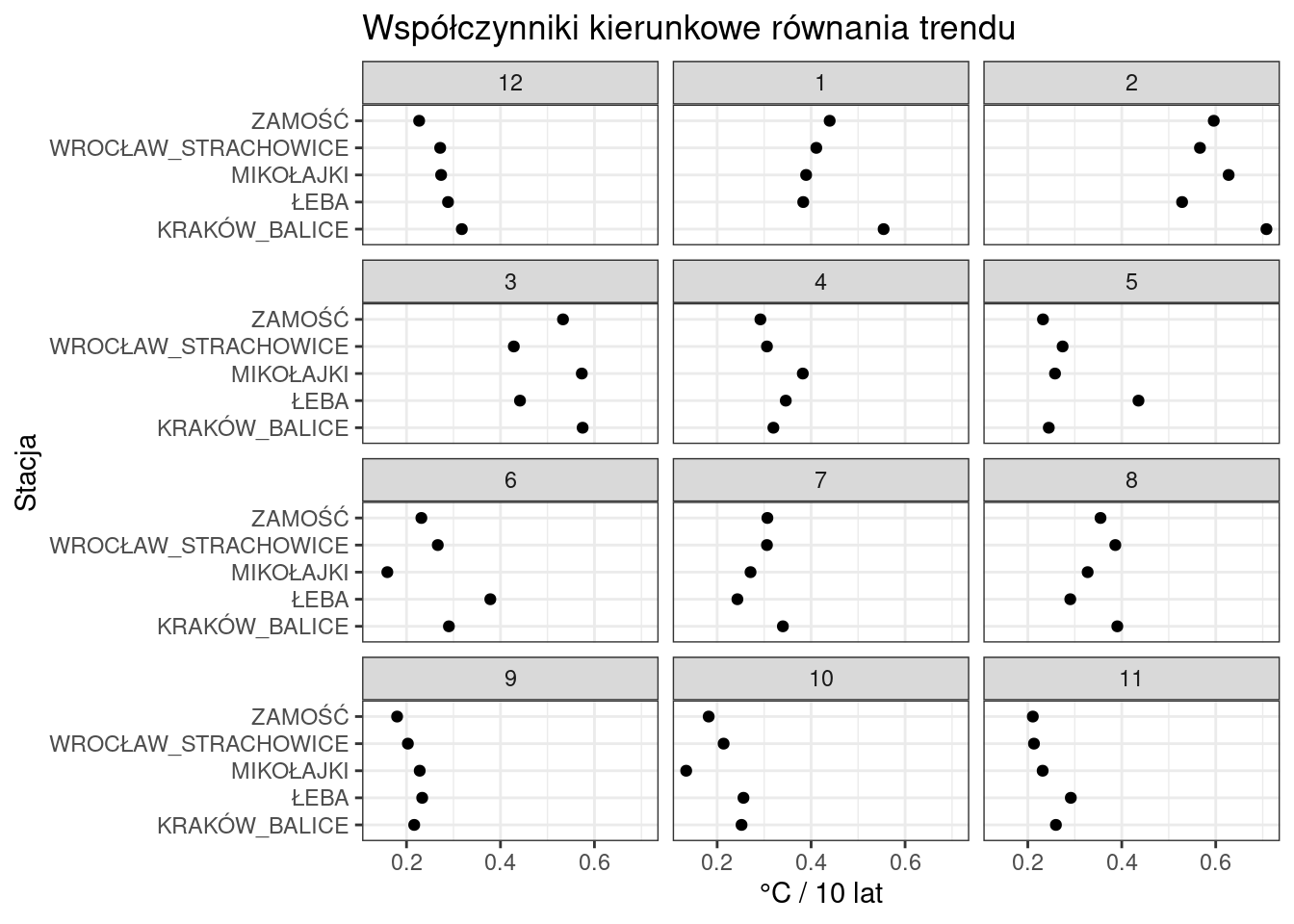
Ostatnim etapem będzie pokolorowanie punktów w zależności czy trend jest istotny statystycznie. W tym celu obliczymy wartości p-value w analogiczny sposób co wartości współczynników kierunkowych.
p_values <- data %>%
group_by(STATION, MONTH) %>%
summarise(P_VALUE = summary(lm(T2M~YEAR))$coefficients[2, 4])p_values# A tibble: 60 × 3
# Groups: STATION [5]
STATION MONTH P_VALUE
<chr> <dbl> <dbl>
1 KRAKÓW_BALICE 1 0.00143
2 KRAKÓW_BALICE 2 0.000257
3 KRAKÓW_BALICE 3 0.0000255
4 KRAKÓW_BALICE 4 0.000453
5 KRAKÓW_BALICE 5 0.00191
6 KRAKÓW_BALICE 6 0.0000612
7 KRAKÓW_BALICE 7 0.00000476
8 KRAKÓW_BALICE 8 0.0000000420
9 KRAKÓW_BALICE 9 0.00641
10 KRAKÓW_BALICE 10 0.00313
# ℹ 50 more rowsPołączymy teraz ramkę danych współczynniki z ramką p_values
wspolczynniki <- wspolczynniki %>%
left_join(p_values, by = c("STATION", "MONTH"))wspolczynniki# A tibble: 60 × 5
# Groups: STATION [5]
STATION MONTH COEFF MONTHord P_VALUE
<chr> <dbl> <dbl> <fct> <dbl>
1 KRAKÓW_BALICE 1 0.554 1 0.00143
2 KRAKÓW_BALICE 2 0.708 2 0.000257
3 KRAKÓW_BALICE 3 0.575 3 0.0000255
4 KRAKÓW_BALICE 4 0.320 4 0.000453
5 KRAKÓW_BALICE 5 0.245 5 0.00191
6 KRAKÓW_BALICE 6 0.290 6 0.0000612
7 KRAKÓW_BALICE 7 0.340 7 0.00000476
8 KRAKÓW_BALICE 8 0.391 8 0.0000000420
9 KRAKÓW_BALICE 9 0.216 9 0.00641
10 KRAKÓW_BALICE 10 0.252 10 0.00313
# ℹ 50 more rowsI dodamy zmienna SIG, w której wpiszemy kolor “red”, jeżeli p-value jest mniejsza niż 0,05 lub “blue” jeżeli jest większa lub równa.
wspolczynniki <- wspolczynniki %>%
mutate(SIG = ifelse(P_VALUE < 0.05, "red", "blue"))
wspolczynniki# A tibble: 60 × 6
# Groups: STATION [5]
STATION MONTH COEFF MONTHord P_VALUE SIG
<chr> <dbl> <dbl> <fct> <dbl> <chr>
1 KRAKÓW_BALICE 1 0.554 1 0.00143 red
2 KRAKÓW_BALICE 2 0.708 2 0.000257 red
3 KRAKÓW_BALICE 3 0.575 3 0.0000255 red
4 KRAKÓW_BALICE 4 0.320 4 0.000453 red
5 KRAKÓW_BALICE 5 0.245 5 0.00191 red
6 KRAKÓW_BALICE 6 0.290 6 0.0000612 red
7 KRAKÓW_BALICE 7 0.340 7 0.00000476 red
8 KRAKÓW_BALICE 8 0.391 8 0.0000000420 red
9 KRAKÓW_BALICE 9 0.216 9 0.00641 red
10 KRAKÓW_BALICE 10 0.252 10 0.00313 red
# ℹ 50 more rowsMamy już zatem wszystkie niezbędne informacje, aby zrobić kolejny upgrade naszego wykresu.
ggplot(wspolczynniki, aes(x = STATION, y = COEFF))+
geom_point(aes(color = SIG))+
labs(
title = "Współczynniki kierunkowe równania trendu",
x = "Stacja",
y = "°C / 10 lat"
)+
facet_wrap(~MONTHord, ncol = 3)+
theme_bw()+
coord_flip()+
scale_color_manual(values = c("red" = "red", "blue" = "blue"))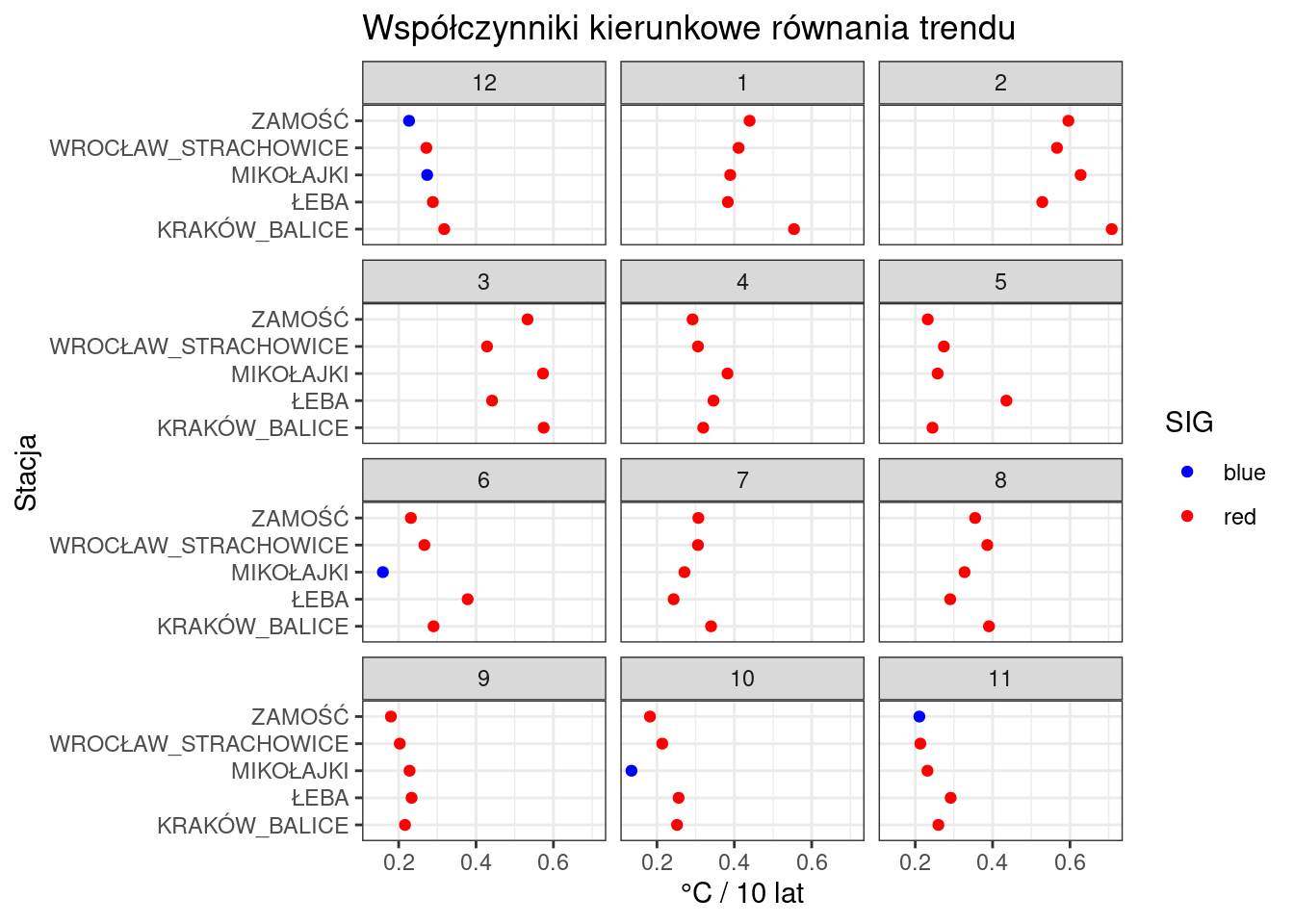
Usuńmy jeszcze legendę i dodajmy nieco informacji w tytule. Oczywiście, w przypadku publikacji naukowych nie stosuje się tytułów na wykresach. Wszystkie niezbędne informację przekazywane są w tytule umieszczanym zazwyczaj pod wykresem.
I jeszcze odrobina własnoręcznie zdefiniowanych parametrów
my_style <- theme(text = element_text(size = 14),
panel.border = element_rect(colour = "black", fill = NA, linewidth = 1))ggplot(wspolczynniki, aes(x = STATION, y = COEFF))+
geom_point(aes(color = SIG))+
labs(
title = "Współczynniki kierunkowe trendu temperatury powietrza\nna wybranych stacjach synoptycznych w Polsce",
subtitle = "1951-2024",
x = "Stacja",
caption = "źródło danych: ERA5",
y = "°C / 10 lat"
)+
facet_wrap(~MONTHord, ncol = 3)+
coord_flip()+
scale_color_manual(values = c("red" = "red", "blue" = "blue"))+
theme_bw()+
theme(legend.position = "none")+
my_style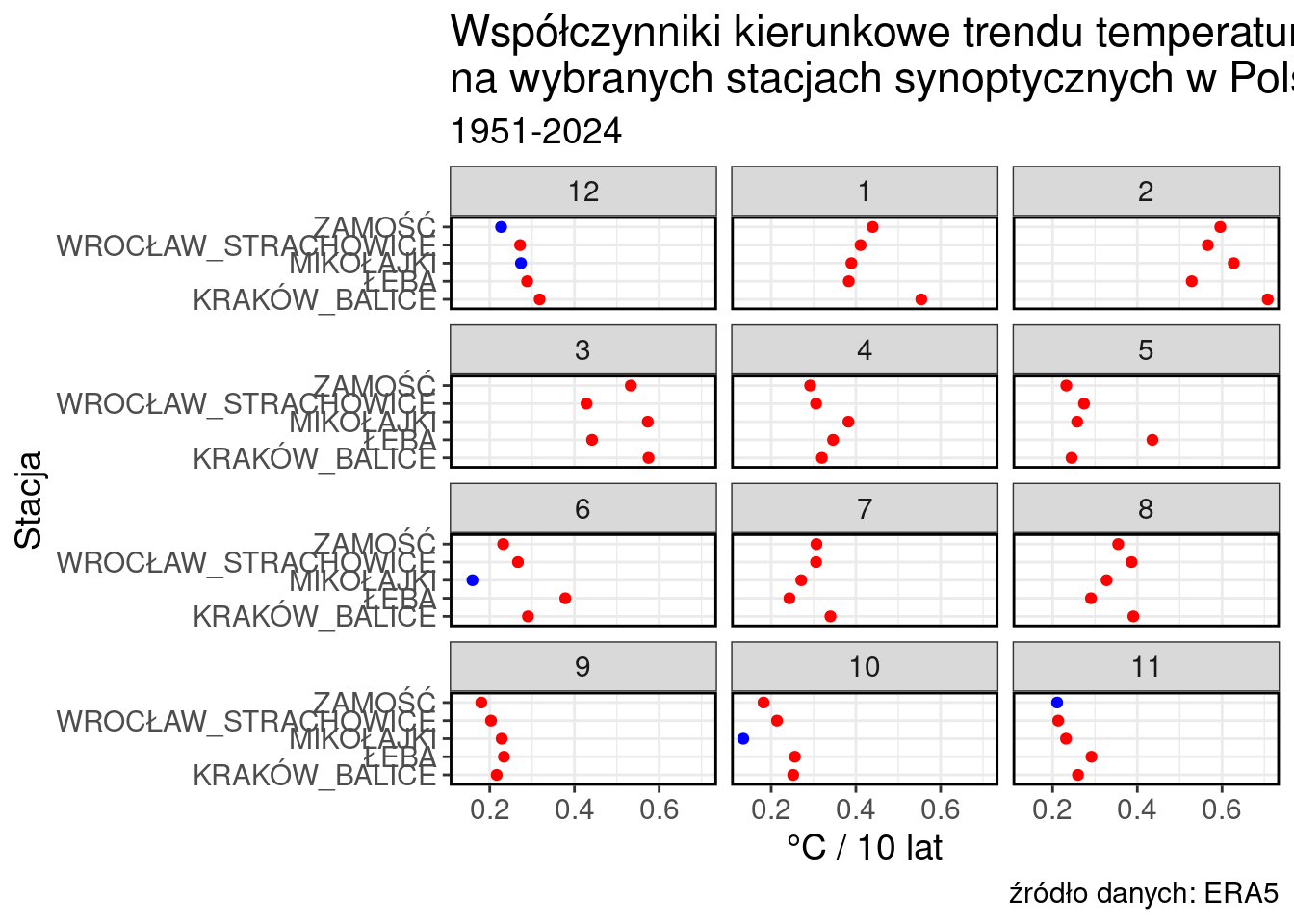
Nie przejmujemy się za bardzo nachodzącymi na siebie etykietami stacji albo znikającym za marginesem tytułem. Wynika to czasami z domyślnych wartości rozmiaru wykresu w R. Po eksporcie powinno wyglądać OK.
Dopasowanie parametrów graficznych czasami wymaga pewnej finezji, ale jak już raz to zrobimy to później w zasadzie odbywa się to w trybie copy/paste, a wszystkie nasze wykresy wyglądają spójnie.
Zapiszmy plik w formacie jpg w katalogu roboczym.
ggsave(filename = "trendy.jpg",
dpi = 300,
width = 10,
height = 8,
units = "in")U mnie finalny wykres po eksporcie wygląda następująco
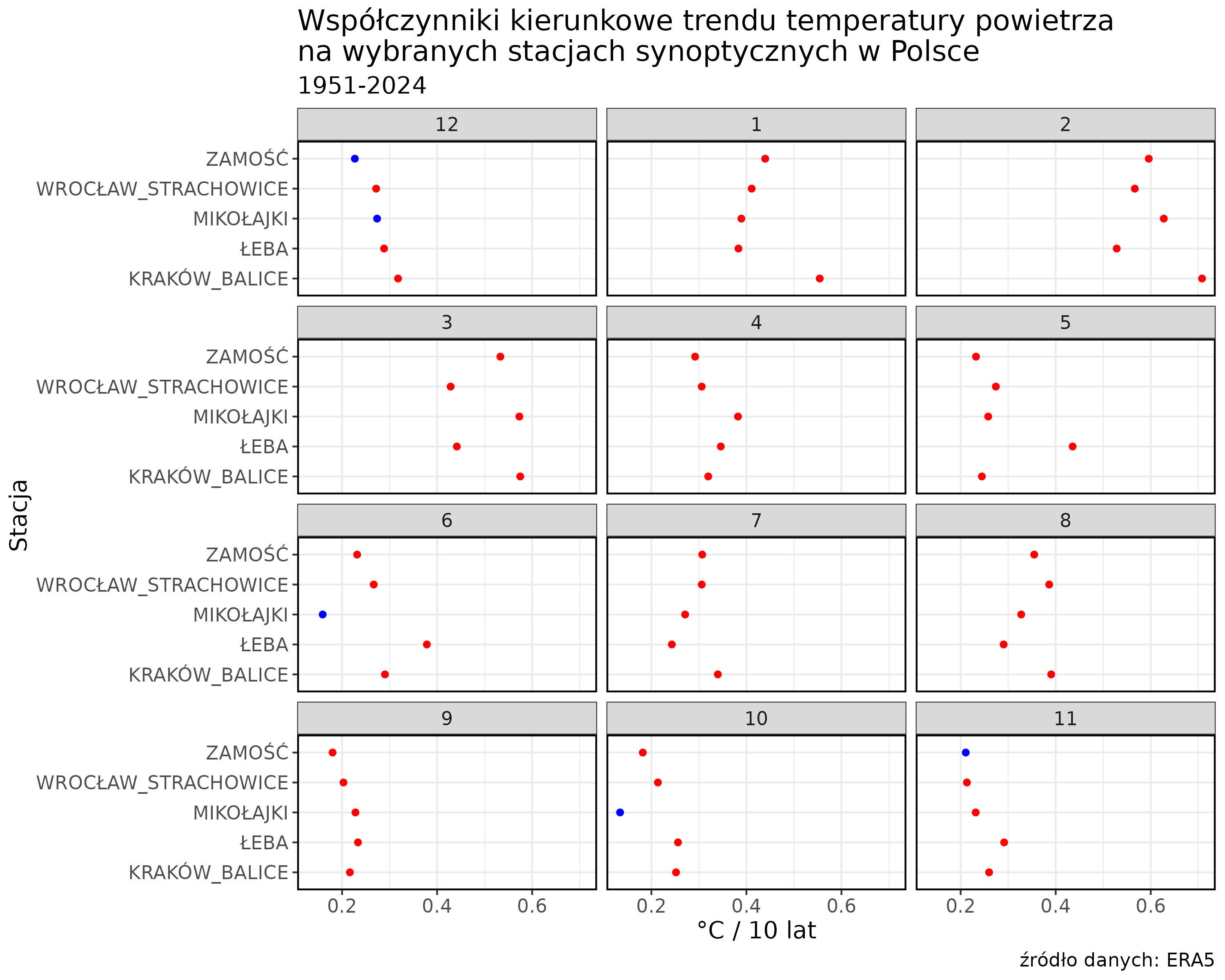
Powyższe stanowi jedynie wycinek możliwości R. W przypadku tredndów można np. zastosować test nieparametryczny Mann’a-Kendall’a, lub obliczać współczynniki i istotność statystyczną dla całego zakresu możliwych długości serii przekraczających np. 30 lat, różnicując momenty startu.
Po więcej zapraszamy na kursy DataCraft LAB.